Bedeutung und Funktion von Information Gain für SEO und LLMO: Erfolg durch einzigartige Informationen
Bedeutung und Funktion von Information Gain für SEO und LLMO: Erfolg durch einzigartige Informationen https://patrickstolp.de/wp-content/uploads/2025/07/information-gain-seo-llmo.jpg 1024 1024 Patrick Stolp https://secure.gravatar.com/avatar/6bdd2bf10b32556ccbe5a3b16931cb997c2c973524b74b20c375f7c9174c3ecd?s=96&d=blank&r=gWer heute eine Frage an ein Suchsystem stellt, gibt sich mit einer Liste blauer Links nur noch selten zufrieden, seitdem es generative KI gibt. Die Suchergebnisse von einst (Google und Co.), die einem reinen Katalog von Websites glichen, aus dem man sich über das Sichten und Lesen unterschiedlicher Quellen seine eigene beste Antwort selbst zusammensetzen musste, weichen zunehmend direkten, oft erstaunlich – informativen – Antworten, die unmittelbar auf der Ergebnisseite präsentiert werden (ChatGPT und andere KI-Chatbots).
Moderne Suchsysteme haben aufgehört, einzelne Wörter oder Verweise zu zählen und zu verarbeiten. Sie haben begonnen, das Wesen von Information selbst zu ergründen, indem sie aus reinen „strings“ mehr und mehr „things“ werden ließen. Maschinen verknüpften Begriffe und Begriffskombinationen, erfassten so ihren Kontext und gewannen einen Eindruck davon, ob und in welchem Maße diese einen Beitrag zum Informationsgewinn leisten können – oder eben auch nicht. Diese tiefere Ebene des Verständnisses ist die eigentliche Revolution der Suche, die in unserer Gegenwart durch „conversational content“ ihre Manifestation findet.
Wer also, wie ich, im künftigen digitalen Search Marketing, also in der Suchmaschinenoptimierung (SEO) oder der aufkommenden Disziplin der Large Language Model Optimization (LLMO), erfolgreich sein will, muss diesen Wandel im Kern verstehen.
In diesem Artikel beleuchte ich daher das Konzept des Information Gain, das nicht nur den (menschlichen) Informationsgewinn messbar macht, sondern Maschinen in die Lage versetzt, ein Wissensnetzwerk durch semantische Verknüpfungen zu entwickeln. Abschließend erläutere ich, wie generative KI aus diesen Informationen und Informationsmetriken kohärente und nützliche Antworten erschafft.
Wie Suchmaschinen lernten, Informationen zu verstehen
Um die Genialität moderner Suchsysteme zu würdigen, muss ich einen Schritt zurückgehen. In den Anfängen war die digitale Suche ein recht mechanischer Prozess. Man kann sich das bildlich vorstellen wie den Index am Ende eines gewaltigen Sachbuchs: Suchmaschinen haben für jedes einzelne Wort eine Liste aller Seiten erstellt, auf denen es vorkam. Der Index kannte also die genaue Position von Begriffen wie „Golf“ oder „Testbericht“, aber er verstand nicht, dass diese Wörter in einer bestimmten Kombination eine spezifische und eindeutige Bedeutung erhalten.
Suchsysteme waren also kontextblind. Bei einer Suche nach „Golf GTI Testbericht“ lieferte eine Suchmaschine einfach alle Dokumente, die irgendwo in einem Dokument diese Wörter enthielten. Das Ergebnis konnte ein Bericht über ein Golfturnier, das vom Rügener Flughafen mit der internationalen Kennung „GTI“ gesponsert wurde, sein, was vermutlich nur selten die Intention gewesen wäre, oder ein „Testbericht“ über ein Automodell von Volkswagen. Das System scheiterte also daran, zu erkennen, dass der Nutzer einen ganz bestimmten Informationskontext suchte.
Phrase-based indexing
Der erste große Durchbruch zur Überwindung dieser Starrheit war die phrasenbasierte Indexierung. Doch wie entscheidet eine Maschine, welche Phrasen zusammengehören und welche nicht?
Die Antwort liegt in einem Konzept, das aus der Informationstheorie und dem maschinellen Lernen entlehnt ist und in Patenten wie US7536408B2 eine zentrale Rolle spielt: die Berechnung des Information Gain.
Um dies zu verstehen, müssen wir zwei Kernbegriffe kennen:
- Entropie: Stell Dir einen Korb mit gemischten Früchten aller Art vor. Die Entropie ist hier sehr hoch, es herrscht Unordnung bzw. Chaos. Wenn Du die Früchte nun nach Sorten in kleinere Schalen sortierst, sinkt die Entropie in jeder einzelnen Schale. Entropie ist also ein Maß für die Unreinheit oder Zufälligkeit in einem Datensatz.
- Entscheidungsbäume: Ein Entscheidungsbaum ist ein Modell, das versucht, diese Unordnung zu reduzieren, indem es eine Reihe von Fragen stellt. Zum Beispiel: „Ist die Frucht rot?“. Jede Antwort teilt den großen Korb in zwei kleinere, geordnetere Gruppen auf.
Information Gain ist nun die exakte mathematische Metrik, die berechnet, welche Frage die Unordnung am effektivsten reduziert. Die Formel lautet im Kern:
Information Gain = Entropie (vor der Frage) – Durchschnittliche Entropie (nach der Frage)
Eine Frage, die zu einem hohen Information Gain führt, ist also eine sehr gute Frage, weil sie viel Klarheit schafft.
Übertragen auf die Suchmaschine ist die Frage eines Suchsystems: „Sagt das Vorhandensein der Phrase A etwas über das Vorhandensein der Phrase B aus?“
Durch die Berechnung des Information Gain konnte eine Suchmaschine also quantifizieren, welche Phrasen starke, vorhersagbare Beziehungen zueinander haben und welche nur zufällig zusammen auftreten.
Statt Dokumente nur unter einzelnen Wörtern abzulegen, begann das System, sie aktiv mit Metadaten über semantische Beziehungen anzureichern.
Konkret kann man sich das so vorstellen: Ein Dokument wurde nun nicht mehr nur für das Vorkommen des Wortes „GTI“ indiziert, sondern für die „gute Phrase“ „Golf GTI Testbericht“. Der entscheidende Schritt war jedoch die Annotation: Dieses Dokument wurde im Index zusätzlich mit einem Vektor – der in diesem Kontext als eine Art digitales Etikett fungierte – versehen, der eine Liste von thematisch verwandten Phrasen repräsentierte. Diese verwandten Phrasen (z. B. „Beschleunigung“, „PS-Zahl“, „Kompaktsportler“) wurden zuvor über den Information Gain als hochgradig relevant identifiziert und zu Clustern zusammengefasst.
Das Ergebnis war ein Wissensnetzwerk, das direkt im Index verankert war. Die Suchmaschine konnte nun bei einer Anfrage nicht nur Dokumente finden, die die exakten Suchphrasen enthielten, sondern auch solche, die thematisch relevant waren, weil sie mit den passenden semantischen Clustern annotiert waren. Die eigentliche Informationsmehrwert lag nicht mehr nur im einzelnen Wort, sondern in den explizit im Index gespeicherten relevanten Beziehungen zwischen den Worten.
Information Gain aus Nutzerperspektive: Wie neu sind die Informationen eines Dokuments (speziell für dich)?
Ich fasse nochmal kurz den Wert von Information Gain für Maschine bzw. Suchsysteme zusammen: Zunächst dient der Information Gain als internes Werkzeug zur Qualitätskontrolle des Index. Funktionelle Aufgabe ist es, aus dem riesigen Ozean an Daten sinnvolle Zusammenhänge herauszufiltern. Phrasen, die nur zufällig nebeneinanderstehen, erzeugen informatives „Rauschen“ und werden durch einen niedrigen Information-Gain-Wert entlarvt und aussortiert. Gleichzeitig werden Phrasen mit hohen gegenseitigen Information-Gain-Werten zu semantischen Clustern zusammengefasst. Dies ist die Perspektive der Maschine: die Schaffung einer sauberen, logisch geordneten Wissenslandkarte.
Auf dieser Grundlage entfaltet sich die zweite, für den menschlichen Endnutzer letztlich relevante Perspektive: der „Neuheitsgrad“ einer Information bzw. eines Dokuments. Auch dieses Verständnis von Information Gain ist nicht etwa Ausdruck bloßer Zufälligkeit, sondern basiert auf einem wohldefinierten mathematischen Prinzip, umgesetzt durch Machine-Learning-Modelle: dem Rückgang der Entropie, also der mittleren Ungewissheit innerhalb einer Wahrscheinlichkeitsverteilung.
„Neu“ ist Information in diesem Sinne dann, wenn sie bestehende Erwartungen, in diesem Fall konkret den gegenwärtigen Wissensstand eines Nutzers, systematisch korrigiert oder präzisiert.
Man kann sich den Prozess des Information Gains für einen Nutzer grundsätzlich so vorstellen:
- Der Startpunkt: Welches Maß an Entropie/Nicht-Wissen hat ein Nutzer?
Google oder ein anderes Suchsystem erfasst die Dokumente, die ein Nutzer zu einem Thema bereits gesehen hat (z. B. Artikel 1, 2 und 3 über „effektives Schreiben von Content-Marketing-Ratgebern“). Diese Sammlung an bekannten Informationsdokumenten repräsentiert den aktuellen Wissensstand des Nutzers, und dieser inhärent ist eine bestimmte informationelle Entropie – gewissermaßen ein Maß für das verbleibende Nicht-Wissen oder die noch unbeantworteten Aspekte des Themas. - Die Weggabelung: Welches Dokument reduziert seine Entropie/sein Nicht-Wissens?
Jedes neue, noch nicht gesehene Dokument (z. B. ein Artikel über „erfolgreiche Content-Distribution von Ratgebertexten) wird als potentieller nächster Schritt in einem Entscheidungsbaum behandelt. Das Suchsystem stellt sozusagen die Frage: Wie stark würde sich die Gesamtunsicherheit (Entropie) des Nutzers reduzieren, wenn ihm dieses Dokument präsentiert wird? - Das Etappenziel: Der Information-Gain-Score
Der Score für den Neuheitswert wird berechnet, indem die Entropie nach dem Lesen des neuen Dokuments von der Entropie davor abgezogen wird, exakt also wie weiter oben für Information Gain aus maschineller Perspektive schon formuliert. Ein Dokument, das nur bereits bekannte Fakten wiederholt, reduziert die Unsicherheit ergo kaum bis gar nicht – der Information-Gain-Score ist niedrig. Ein Dokument, das einen völlig neuen Aspekt beleuchtet (in unserem Beispiel die Distribution anstatt Produktion von Content), sorgt für eine im Vergleich höhere Reduktion der Entropie und erhält daher einen hohen Information Gain Score.
In diesem Google-Patent mit dem Titel Contextual estimation of link information gain wird dieser Prozess sogar nahezu exakt so beschrieben, auch wenn Entropie als zugrunde liegendes mathematisches Modell, soweit ich es verstehe – nicht genannt wird, so viel Ehrlichkeit soll sein.
Ein kleiner Einschub am Rande: Ich bin weder Informatiker noch Mathematiker. Ich meide Zahlen und Formeln wie der Teufel das Weihwasser. Trotzdem bin ich der Meinung, dass es ohne grundlegendes Verständnis von Kernmechanismen des Machine Learning künftig nicht mehr geht. Sie dazu meinen LinkedIn-Post:
Synthese zweier Information-Gain-Konzepte: Ordnung als Voraussetzung für Neuheit
Beide dargestellten Perspektiven auf Information Gain sind keine Gegensätze, sondern zwei Seiten derselben Medaille. Ein System, ob semantische Suchmaschine oder LLM bzw. KI-Chatbot, kann den Neuheitswert eines Dokuments für einen Nutzer (menschliche Perspektive) nur dann präzise bestimmen, wenn es zuvor die grundlegenden thematischen Zusammenhänge im gesamten Datenkorpus verstanden und geordnet hat (maschinelle Perspektive).
Um zu erkennen, dass der Artikel aus meinem Beispiel über Content-Distribution subjektiv neu und relevant ist, muss die Maschine wissen – oder berechnet haben -, dass „Content-Distribution“ und „Content-Produktion“ zwei unterschiedliche, aber zum Wissensgebiet „Content-Marketing“ gehörende semantische Cluster sind. Das Fundament der maschinellen Ordnung ermöglicht erst die „wissenserweiternde“, personalisierte Auswahl und Auslieferung passender Dokumente.
Von der Informationsfindung zur Informationserzeugung
Nachdem die Systeme gelernt hatten, Dokumente thematisch zu vernetzen, war der nächste logische Schritt eine weitere Verfeinerung des Informationssuchsystems: Weg vom ganzen Dokument hin zum einzelnen, relevantesten Textabschnitt bzw. einer (Text-)Passage, um im Wortlaut des zentralen Patents mit dem Namen „Scoring candidate answer passages“ zu bleiben.
Und warum das Ganze? Anstatt dem Nutzer nur eine Liste relevanter Dokumente auf der SERP zu präsentieren, aus denen dieser sich die Antwort selbst heraussuchen musste, sollte ihm nun die präziseste Antwort direkt präsentiert werden , oft in Form der bekannten „Answer Boxes“ oder „Featured Snippets“. (Ergänzung: Für Google ist es seit jeher das Ziel, den Nutzer im Google-Kosmos gefangen zu halten, siehe AI Overviews, aber das ist ein anderes Thema.)
Das Scoring geeigneter Textabschnitte allem voran durch Google funktioniert in mehreren Schritten: Zuerst identifiziert das System eine Nutzeranfrage als „antwortsuchend“. Daraufhin werden aus den relevantesten Dokumenten einzelne „Kandidaten-Passagen“ extrahiert.
Diese Abschnitte, oft direkt unterhalb von (Zwischen-)Überschriften, durchlaufen dann ein ausgeklügeltes, mehrstufiges Bewertungsverfahren, welches sich grob in drei Scoring-Kategorien bzw. Aufgaben unterteilen lässt:
- Passt ein Textabschnitt exakt zur Nutzerfrage (Query Dependent Score)?
- Wie hoch ist die Qualität der Quelle (Query Independent Score)?
- In welchem Kontext steht der Abschnitt, also wie weit ist dieser in der Seitenstruktur bzw. in der strukturgebenden Überschriften-Hierarchie verschachtelt (Context Score)?
Wichtig dabei: Die anfängliche Auswahl der relevanten Dokumente, aus denen diese Passagen stammen, basiert weiterhin auf den fundamentalen Prinzipien des semantischen Index, der mithilfe von Information Gain aufgebaut wurde, wie ich es oben erklärt hatte.
Doch der bisher größte evolutionäre Sprung verwandelte die Suchmaschine vom Informations-Bibliothekar zum Informations-Autor – es vollzog sich also eine Entwicklung der bloßen Ordnung und Sortierung relevanter und „guter“ Informationsquellen („zehn blaue Links“) zur Extrahierung und Erzeugung der Information an sich. Wir sind in der Gegenwart angekommen. Willkommen in der Ära der generativen KI.
Retrieval Augmented Generation als die logische Weiterentwicklung von Information Gain
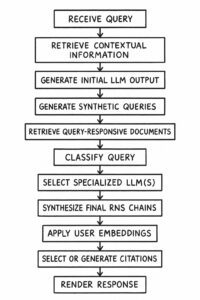
Wir haben festgestellt, dass der entscheidende evolutionäre Sprung in der Fähigkeit liegt, aus gefundenen Informationen eine neue, kohärente Antwort zu erzeugen. Das Herzstück dieser neuen Generation von Suchsystemen ist ein Verfahren namens Retrieval-Augmented Generation (RAG). Doch wie stellt man sicher, dass dieser Prozess nicht nur kreativ, sondern vor allem faktisch korrekt und nachvollziehbar ist?
Die Antwort darauf liefern ausgeklügelte Methoden wie GINGER (Grounded Information Nugget-Based Generation of Responses), ein System, das von Forschern der Universität Stavanger entwickelt wurde. Es löst die Kernprobleme bisheriger RAG-Modelle – wie faktische Fehler, fehlende Quellenbelege und das „Lost in the Middle“-Problem bei langen Kontexten – durch einen genialen, mehrstufigen Ansatz. Die zentrale Innovation von GINGER ist, dass es nicht mit ganzen Textpassagen arbeitet, sondern diese zuerst in ihre atomaren Bestandteile zerlegt: in sogenannte Information Nuggets. Das sind minimale, in sich geschlossene und überprüfbare Informationseinheiten, die eine präzise Rückverfolgung zur Quelle ermöglichen.
Der gesamte Prozess lässt sich am besten als eine Art Fertigungsstraße für Antworten verstehen:
- Zerlegung in Nuggets: Zuerst extrahiert ein LLM aus den relevantesten gefundenen Textpassagen die zentralen Fakten als prägnante Nuggets.
- Ordnen der Fakten: Anschließend werden diese Nuggets thematisch geclustert, um Redundanz zu vermeiden und die verschiedenen Aspekte (Facetten) einer Anfrage zu ordnen. Dies erhöht die Informationsdichte der späteren Antwort.
- Priorisierung der Themen: Die erstellten Themencluster werden nach ihrer Relevanz für die Anfrage bewertet und sortiert, um die wichtigsten Informationen zu priorisieren.
- Verfassen der Antwort: Zuletzt fasst ein LLM die Kernaussagen der wichtigsten Cluster zu einzelnen Sätzen zusammen und glättet diese in einem finalen Schritt zu einer flüssigen, gut lesbaren Antwort, ohne neue Inhalte hinzuzufügen.
Dieses GINGER-Verfahren stellt sicher, dass die finale Antwort maximal informativ, faktisch fundiert und frei von Redundanz ist – eine massive Verbesserung gegenüber einfachen RAG-Ansätzen.
Der Zusammenhang von RAG und Information Gain
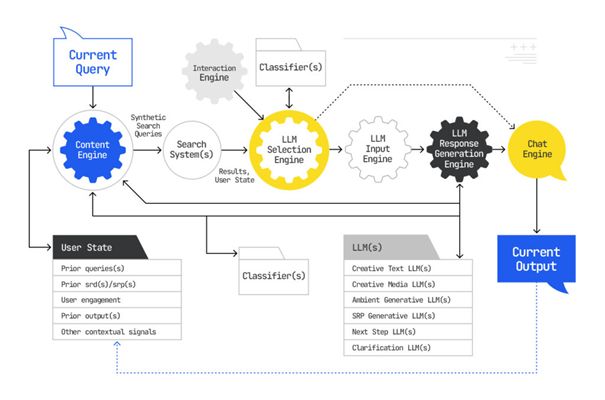
Dieses ausgeklügelte Verfahren beginnt, wie wir sahen, mit dem „Retrieval“, also dem Abrufen relevanter Textpassagen. Dies führt uns zu einer entscheidenden technischen Frage: Woher nimmt das System diese Informationen?
Dafür muss man zwischen zwei Arten von Such-Systemen unterscheiden: Ein eigenständiges LLM ohne Zugang zu Suchmaschinendokumenten besitzt keinen durchsuchbaren Index; sein Wissen ist statisch in den Modellparametern eingebrannt. Eine klassische Suchmaschine hingegen basiert auf einem gigantischen, durchsuchbaren Index des Webs.
Moderne RAG-Systeme auf der Basis von GINGER kombinieren nun das Beste aus beiden Welten: Sie nutzen das Sprachverständnis eines LLM, geben ihm aber Zugriff auf einen externen, durchsuchbaren Index, aus dem es Fakten abrufen kann.
Genau hier wird die Verbindung zum Information Gain fundamental:
1. Information Gain als Motor für das Retrieval (Die System-Perspektive)
Die „R“-Komponente in RAG, der Retriever, benötigt einen Index, der semantische Zusammenhänge versteht, um die qualitativ besten Passagen zu finden. Die Prinzipien des maschinenzentrierten Information Gains – also Phrasen zu erkennen und anhand ihrer Beziehungen zu Clustern zu verbinden – sind die technologische Grundlage, die einen solchen intelligenten Index erst ermöglichen. Man kann also sagen: Das maschinelle Konzept des Information Gain sorgt dafür, dass die Rohstoffe für die generative KI von höchster Qualität und Relevanz sind.
2. Information Gain als Ziel für die Generation (Die Nutzer-Perspektive)
Die „G“-Komponente in RAG, der Generator, hat das Ziel, eine kohärente, nicht-redundante und maximal informative Antwort zu erstellen. Dieses Ziel deckt sich perfekt mit dem nutzerzentrierten Verständnis von Information Gain. Obwohl Systeme wie GINGER nicht explizit die Entropie-Formel verwenden, ist ihre Architektur darauf ausgelegt, genau dieses Prinzip umzusetzen: Das Clustering von Nuggets zur Vermeidung von Redundanz und das Ranking der Themencluster zur Priorisierung der wichtigsten Fakten sind beides Mechanismen, die darauf abzielen, dem Nutzer den größtmöglichen Wissensgewinn zu verschaffen.
Das nutzerzentrierte Prinzip des Information Gain beschreibt also exakt das Ziel, das fortschrittliche RAG-Systeme durch ihre komplexe Architektur zu erreichen versuchen.
Information Gain ist somit der unsichtbare Faden, der die gesamte Evolution der Suche verbindet. In seiner maschinenzentrierten Form schafft er die semantisch geordnete Grundlage, die den Retriever von RAG-Systemen leistungsfähig macht. Gleichzeitig beschreibt er in seiner nutzerzentrierten Form exakt das Ziel, das fortschrittliche Generatoren wie GINGER anstreben: die Schaffung einer faktisch korrekten, redundanzfreien und maximal aufschlussreichen Antwort.