
Google AI Mode: Funktion & Prozessschritte auf Basis von Google-Patenten erklärt
Google AI Mode: Funktion & Prozessschritte auf Basis von Google-Patenten erklärt https://patrickstolp.de/wp-content/uploads/2025/05/ai-mode-funktionsweise.jpg 1024 708 Patrick Stolp https://secure.gravatar.com/avatar/6bdd2bf10b32556ccbe5a3b16931cb997c2c973524b74b20c375f7c9174c3ecd?s=96&d=blank&r=gSEO ist nicht tot. SEO ist gestorben und wieder auferstanden. SEO ist ein Zombie. Oder um es etwas philosophischer auszudrücken: In klassischer SEO waren die Optimierungsmaßnahmen für die Suchmaschine deterministisch.
Im Google-Kosmos befanden wir uns innerhalb einer gewissen regelbasierten Ordnung. Klar, viele Rankingfaktoren waren offiziell nicht bekannt, aber man wusste, dass diese klar definiert waren und algorithmischen Regeln folgten. Der Effekt von Maßnahmen war reproduzierbar, und: Wenn du oder ich eine Suchanfrage in die Google-Suchmaske eingaben, dann war das Endergebnis für dich wie für mich (fast) identisch.
Das ist auch immer noch der Fall. Aber die Zukunft hat begonnen und die klassische Suche – und somit das Handwerk der Suchmaschinenoptimierung – weichen einer eher probabilistischen Weltenordnung durch Sprachmodelle wie ChatGPT, Gemini und, damit verbunden, dem neuen Google AI Mode.
Damit einher geht eine gewisse Inkonsistenz. Ein LLM kann auf denselben Prompt bzw. dieselbe Suchanfrage zum Beispiel zehn unterschiedliche Meta-Descriptions generieren, die alle „gut“ sein können, aber sich im Stil und Fokus leicht unterscheiden, eben weil es keine deterministische, „die eine richtige“ Option gibt.
Auch deswegen wird häufig abgestritten, dass es bei der „Next-Token-Vorhersage“ auch nur irgendein Verständnis im eigentlichen Sinn gebe. Aber ist dies überhaupt möglich? Ich bin kein Data Scientist und maße mir eine selbstbewusste Meinung nur in meinen Fachgebieten an. Aber als erfahrender SEO, der sich seit langer Zeit mit Technologien des Machine Learning befasst, stelle ich daher dennoch die Frage, inwieweit eine sinnvolle Vorhersage unabhängig einem wenigstens impliziten Verständnis der (menschlichen) Realität möglich sein sollte. Zusammengefasst bedeutet dies für mich: Ein Sprachmodell versteht nicht, weil es „weiß“, sondern weil es gut „rät“ – und das gelingt nur, wenn seine Wahrscheinlichkeitsverteilung die zugrunde liegende Realität approximiert.
Entgegen aller „SEO-Regeln“ war dies bewusst eine sehr abstrakte und für semantische Suchmaschinen eher nicht vorteilhafte Einleitung für das Kernthema dieses Artikels: Googles neuen AI Mode. Diese ausufernde Hinführung zum Artikel zeigt aber schon, wie komplex die Gegenwart für Fachleute aus dem Search Marketing ist.
Im Folgenden werde ich den aktuellen (Wissens-)Stand aufzeigen, was uns Google-Patente über die Funktionsweise des AI Mode sagen können, was die Kernkonzepte Reasoning, Dense und Sparse Retrieval, Passage-Level Retrieval sowie User Embeddings bzw. Personalisierung in diesem Kontext bedeuten. Dieser Artikel ist die Einleitung für kommende Artikel zur eigentlichen Kernfrage: was alle neuen Erkenntnisse und Technologien eigentlich für uns SEOs – und natürlich unseren Kunden, die weiterhin sichtbar sein wollen – für Auswirkungen haben.
Was ist der Google AI Mode und wie ist der Ablauf von Suchanfrage bis generierter Antwort? – einfach erklärt
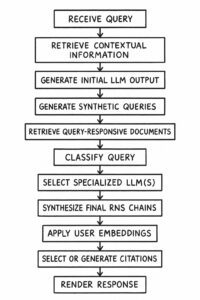
Was für dich bei Nutzung des AI Modes wie eine einzelne, direkte Antwort von Google erscheint, ist in Wahrheit das Resultat eines hochkomplexen wie mehrstufigen Prozesses im Hintergrund. Der AI Mode orchestriert eine Kette von Operationen, um zu einem Ergebnis zu gelangen, das über eine simple Dokumentenabfrage weit hinausgeht.
Der Prozess beginnt mit deiner Suchanfrage (Receive Query). Unmittelbar danach greift das System auf kontextuelle Informationen (Retrieve Contextual Information) zu – Daten über deine vorherigen Interaktionen, deinen Standort oder die aktuelle Suchsitzung können hier einfließen. Gleichzeitig erzeugt ein generatives Sprachmodell eine erste, rohe Interpretation deiner Anfrage (Generate Initial LLM Output).
Ein entscheidender Schritt ist die anschließende Zerlegung deiner ursprünglichen Frage. Sie wird intern in ein Netzwerk von synthetischen Folgefragen (Generate Synthetic Queries / Query Fan-Out) aufgefächert. Das System antizipiert damit verwandte Aspekte und implizite Informationsbedürfnisse, die über deine explizite Eingabe hinausgehen. Für jede dieser spezifischen Unterfragen werden dann passende Dokumente und Informationsschnipsel (Retrieve Query-Responsive Documents) aus dem Index identifiziert. Parallel dazu wird deine ursprüngliche Anfrage präzise hinsichtlich Intention und gewünschtem Antwortformat klassifiziert (Classify Query).
Auf Basis dieser Klassifizierung wählt der AI Mode nun spezialisierte Sprachmodelle (Select Specialized LLM(s)) aus. Man kann sich diese als Module vorstellen, die jeweils für bestimmte Aufgaben optimiert sind – etwa für Zusammenfassungen, Vergleiche oder die Extraktion spezifischer Entitäten. Diese Modelle arbeiten dann zusammen und erzeugen logische Schlussfolgerungsketten (Generate Reasoning Chains). Hierbei werden Informationen aus den zuvor abgerufenen Dokumenten nicht nur einfach wiedergegeben, sondern aktiv verarbeitet und in einen logischen Zusammenhang gestellt, um zu einer fundierten Antwort zu gelangen. Die Auswahl der Dokumente stützt sich dabei weniger auf klassische Rankingfaktoren für die ursprüngliche Query, sondern darauf, inwieweit sie einzelne Schritte in dieser maschinellen Argumentationskette stützen.
Die Ergebnisse dieser spezialisierten Modelle und Argumentationsketten werden zu einer kohärenten finalen Antwort synthetisiert (Synthesize Final Response). Bevor diese Antwort jedoch ausgespielt wird, erfährt sie eine weitere, wichtige Anpassung durch sogenannte Nutzer-Embeddings (Apply User Embeddings). Das sind im Grunde vektorisierte Repräsentationen deiner individuellen Präferenzen und bisherigen Nutzerverhaltens. Diese Embeddings ermöglichen eine tiefgreifende Personalisierung, die nicht nur oberflächliche Aspekte der Darstellung betrifft, sondern die Auswahl und Gewichtung der Informationen in der Antwort selbst maßgeblich beeinflussen kann.
Zuletzt werden relevante Quellen ausgewählt oder Zitate für die generierten Aussagen erstellt (Select or Generate Citations), um eine gewisse Nachvollziehbarkeit zu gewährleisten. Erst nach all diesen Schritten wird dir die endgültige, maßgeschneiderte Antwort präsentiert (Render Response).
Was ist der Google AI Mode und wie ist der Ablauf von Suchanfrage bis generierter Antwort? – detaillierte technische Erklärung
Google will selbst mal wieder keine Informationen preisgeben und versucht uns mit dieser über die technischen Grundlagen von AI Overviews und AI Mode absolut nichtssagenden Dokumentation abzuspeisen. Aber so nicht! Deswegen habe ich die Recherche-Maschine angeschmissen und bin tief in mein Patente-Rabbit-Hole abgetaucht. Eine nicht zu verschweigende Vorleistung kam dabei von SEO-Ikone Mike King und seinem Blogbeitrag zum AI Mode.
Zusammenfassend lässt sich sagen, dass der Google AI Mode darauf abzielt, einen Google-Nutzer im Zeitverlauf besser zu verstehen und ihm relevantere Antworten zu liefern. Dieses Ziel wird prozessual so erreicht, dass
- Erstens das System Informationen aus einer Vielzahl abgeleiteter (synthetischer) Suchanfragen extrahiert und
- Zweitens seine Antwort bzw. Antworten durch mehrschichtiges logisches Denken (Reasoning) zusammensetzt.
Das Patent „Search with Stateful Chat“ (US20240289407A1) konzeptioniert dieses System, während das Patent „Query Response from a Custom Corpus“ (US20240362093A1) aufzeigt, wie die letztliche Generierung der Antwort im AI Mode vonstattengeht.
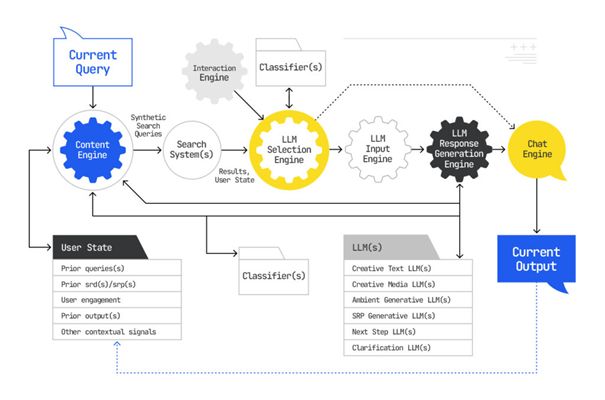
Schritt 1: Kontextualisierung einer Suchanfrage und initiale Dokumentenidentifizierung
Der Grundstein des Google AI Mode ist ein tiefgreifendes, personalisiertes Verständnis des Nutzers und seiner aktuellen Informationsbedürfnisse. Beides wird maßgeblich durch den sogenannten Stateful Context realisiert.
Dieses Systemmerkmal erfasst und berücksichtigt kontinuierlich individuelle Informationen über den Nutzer, wie beispielsweise den Verlauf früherer Suchanfragen, den aktuellen geografischen Standort, verwendete Geräte oder auch spezifische Verhaltenssignale während der Interaktion mit Diensten aus dem Google-Kosmos.
Diese vielfältigen Kontextinformationen werden in numerische Repräsentationen, sogenannte Vektoren bzw. Embeddings, umgewandelt. Diese Embeddings erlauben es dem System, den Nutzerkontext persistent über verschiedene Sitzungen und einzelne Prozessschritte hinweg dynamisch zu berücksichtigen und für die Interpretation von Anfragen und die Personalisierung von Antworten heranzuziehen. Man kann sich dies als eine adaptive Verständnisebene, eine Art Layer, vorstellen, die den gesamten Such- und Antwortgenerierungsprozess überlagert und beeinflusst.
Aufbauend auf diesem dynamischen Nutzerkontext startet bei einer neuen Suchanfrage die Query Fan-Out-Technik. Hierbei wird die ursprüngliche Suchanfrage des Nutzers nicht isoliert betrachtet, sondern dient als Basis für die Generierung einer Vielzahl zusätzlicher, sogenannter synthetischer Suchanfragen durch ein vorgelagertes generatives Modell.
Diese synthetischen Anfragen können thematisch verwandte Aspekte, implizite Annahmen oder mögliche Verfeinerungen der ursprünglichen Intention abdecken. Jede dieser Anfragen (die ursprüngliche und die synthetischen) wird dann genutzt, um im breiten Google-Index oder in spezifisch definierten Datensammlungen nach potenziell relevanten Suchergebnisdokumenten (SRDs) zu suchen.
Die Auswahl dieser ersten Dokumentenmenge erfolgt typischerweise durch den Abgleich der Vektor-Embeddings der verschiedenen Anfragen mit den Embeddings der potenziellen Quelldokumente. Diese initiale Sammlung von Dokumenten bildet die Grundlage für die weitere, verfeinerte Verarbeitung.
Schritt 2: Erstellung und Nutzung des spezifischen Custom Corpus
Die im vorherigen Schritt identifizierten Suchergebnisdokumente (SRDs) werden nun zu einem sogenannten Custom Corpus zusammengefasst. Dieser Begriff beschreibt eine dynamisch erstellte oder vordefinierte, eng abgegrenzte Sammlung von Dokumenten, die vom System als besonders relevant für die spezifische Nutzeranfrage und den aktuellen Nutzerkontext erachtet wird.
Anstatt also potenziell den gesamten Web-Index zu durchsuchen, fokussiert sich das System für die detaillierte Inhaltsanalyse nun auf diesen individuell kontextbezogenen, thematisch eingegrenzten Korpus.
Dieser Custom Corpus dient als primäre und qualitativ hochwertige Informationsquelle für die nachfolgenden Schritte der Antwortgenerierung durch die Google-internen Large Language Models (LLMs). Die Nutzung eines solchen Custom Corpus ermöglicht es, Antworten zu generieren, die auf spezifische Dokumente zugeschnitten sind, ohne dass das zugrundeliegende LLM dafür jedes Mal neu trainiert werden muss.
Schritt 3: Identifizierung und Bewertung relevanter Textpassagen
Nachdem der Custom Corpus mit den relevantesten Dokumenten erstellt wurde, geht der AI Mode in die Tiefe und analysiert diese Dokumente auf der Ebene einzelner Textpassagen (Chunks). Aus den Dokumenten des Custom Corpus werden hierfür zunächst einzelne, in sich geschlossene Textabschnitte extrahiert.
Um die Relevanz dieser Passagen für die ursprüngliche Nutzeranfrage präzise zu bewerten, kommt ein im Patent US20250124067A1 (Method for Text Ranking with Pairwise Ranking Prompting) detailliert beschriebenes Verfahren zum Einsatz: das paarweise Ranking von Textpassagen durch ein Sprachmodell.
Ein generatives Sequenzverarbeitungsmodell (ebenfalls ein LLM) erhält dabei einen Prompt, der die Nutzeranfrage sowie jeweils zwei dieser extrahierten Textpassagen enthält. Basierend auf der Anfrage führt das LLM einen direkten Vergleich zwischen den beiden Passagen durch, um zu entscheiden, welche der beiden die Anfrage besser oder treffender beantwortet bzw. relevantere Informationen liefert.
Das Ergebnis dieses Vergleichs kann unterschiedlich ausgestaltet sein: Entweder generiert das LLM einen Text, der die höhergerankte Passage explizit benennt (z. B.: Passage A ist relevanter als Passage B), oder es gibt einen numerischen Score (z. B. eine Wahrscheinlichkeit oder einen Konfidenzwert) aus, der die relative Präferenz für eine der Passagen quantifiziert. Um die Konsistenz und Zuverlässigkeit dieser Bewertung zu erhöhen, kann der Prozess wiederholt werden, wobei die Reihenfolge der beiden verglichenen Passagen im Prompt vertauscht wird.
Durch die wiederholte Anwendung dieses paarweisen Vergleichs auf eine Vielzahl von Passagen aus dem Custom Corpus erstellt das System eine nach Relevanz geordnete Rangliste der Textpassagen. Diese hochrelevanten und priorisierten Passagen stellen die qualitativ besten „Informationsbausteine“ dar, die dem System nun für die finale Phase der Antwortgenerierung zur Verfügung stehen.
Schritt 4: Klassifikation der Anfrage und Auswahl spezialisierter Antwort-LLMs
Nachdem nun der Pool hochrelevanter Dokumente, also des Custom Corpus, und darin die relevantesten Textpassagen identifiziert und bewertet wurden, erfolgt eine weitere Analyseebene: die Klassifikation der ursprünglichen Nutzeranfrage im Kontext der bisherigen Erkenntnisse.
Basierend auf der Natur der Anfrage, dem etablierten Stateful Context des Nutzers und potentiell auch der Art der gefundenen relevanten Dokumente und Passagen klassifiziert das System die zugrundeliegende Intention des Nutzers und leitet daraus ab, welche Art von Antwort oder welches Darstellungsformat am besten geeignet wäre. Dieser Klassifikationsschritt wird im Patent Search with Stateful Chat (US20240289407A1) beschrieben (siehe FIG. 8 und FIG. 9, insbesondere Blöcke 962 und 964).
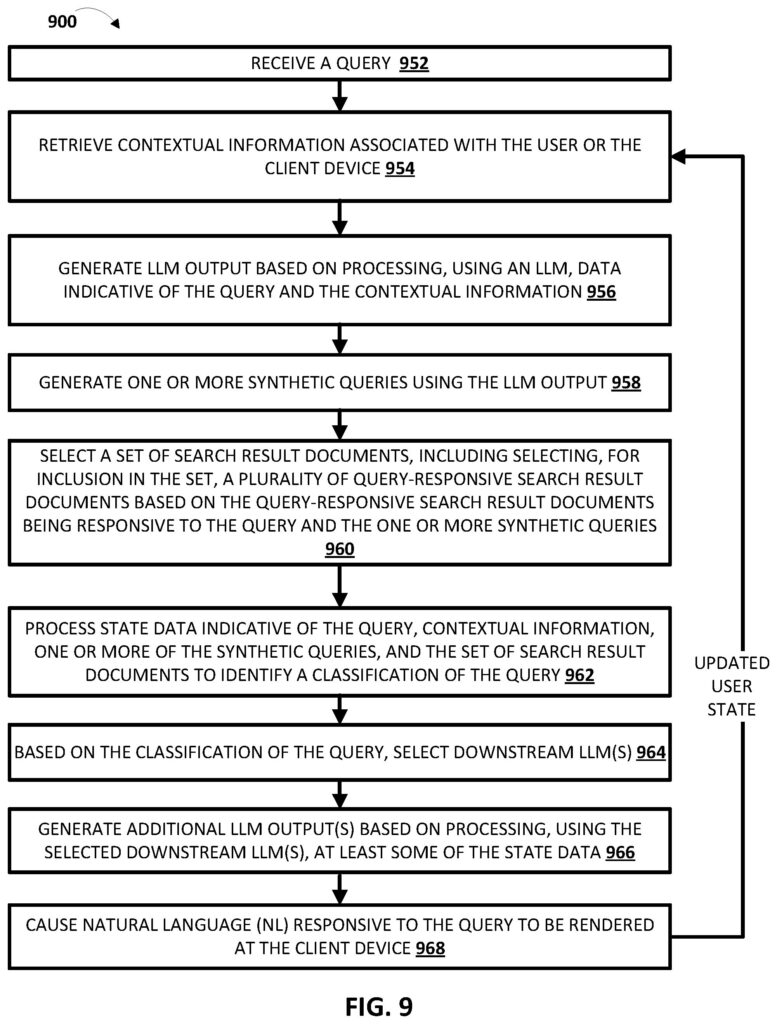
Abhängig von der Klassifikation, ob also beispielsweise eine kreative Texterstellung, eine faktische Zusammenfassung oder Ähnliches benötigt wird, wählt das System dann ein oder mehrere spezialisierte, nachgelagerte Sprachmodelle (Downstream LLMs) aus.
Das Patent Search with Stateful Chat listet hierfür verschiedene Typen von LLMs auf, wie z.B. Creative Text LLM, SRP Generative LLM (für die Zusammenfassung von Suchergebnisseiten), Clarification LLM oder Next Step LLM. Diese spezialisierten Modelle sind jeweils für bestimmte Aufgaben oder Antwortstile optimiert.
Schritt 5: Antwortsynthese und Verlinkung/Zitierung der Quellen
Im finalen Schritt wird die eigentliche Antwort für den Nutzer generiert und mit Quellenbelegen versehen. Dieser Prozess stützt sich auf die Retrieval Augmented Generation (RAG). Das jeweilige Sprachmodell oder die in Schritt 4 ausgewählten, spezialisierten Antwort-LLMs nutzen nun die in Schritt 3 identifizierten und höchstgerankten Textpassagen als fundierte Wissensgrundlage. Diese Passagen dienen als kontextuelle Eingabe, auf deren Basis das LLM eine kohärente und höchstrelevante Antwort auf die ursprüngliche Nutzeranfrage synthetisiert.
Ein entscheidender Aspekt für Transparenz und Nachvollziehbarkeit ist die Verlinkung bzw. Zitierung der verwendeten Quellen. Hierfür kommt eine spezielle Komponente zum Tragen, die in den Patenten US20240362093A1 (Query response using a custom corpus) als „Response Linkifying Engine 138“ und in US20240289407A1 (Search with stateful chat) als ein Mechanismus zur Verifizierung von Antwortteilen beschrieben wird.
Diese Engine hat die Aufgabe, Links oder eindeutige „Dokumentenidentifikatoren“ direkt in die generierte Antwort einzubetten, die auf die Ursprungsdokumente im Custom Corpus verweisen, aus denen die jeweiligen Informationen stammen.
Die (Quellen-)Nennung erfolgt dabei nicht pauschal, sondern basiert auf einer Verifizierung von spezifischen Teilen der generierten Antwort. Wie im Patent US20240289407A1 (insbesondere FIG. 3, Block 360) dargelegt wird, werden einzelne Abschnitte der finalen Antwort mit Passagen aus den Kandidaten-Dokumenten (den SRDs aus dem Custom Corpus) verglichen.
Stellt das System fest, dass ein Quelldokument einen bestimmten Teil der generierten Antwort stützt oder verifiziert, wird dieser Antwortteil mit einem entsprechenden Link zu ebenjenem Dokument versehen. Das bedeutet, dass die Entscheidung für ein Zitat nicht primär von der organischen Rankingposition des Quelldokuments abhängt, sondern davon, inwieweit es spezifische Aussagen in der KI-generierten Antwort direkt belegen kann.
Optimierung für AI Mode nichts anderes als SEO? Nein!
Was bedeuten diese Erkenntnisse nun für uns SEOs? Klar dürfte sein, dass oder das Aufgabengebiet der Large Language Model Optimization (LLMO) bzw. Generative Engine Optimization (GEO) doch anders aussehen wird als klassische Suchmaschinenoptimierung. Was sich nicht ändern wird, ist die Notwendigkeit, sich Googles Systemen anzupassen, und mit „sich“ sind eigene Website-Inhalte gemeint.
Google selbst zielt darauf ab, Informationsbedürfnisse direkter zu befriedigen und den kognitiven Aufwand für Nutzer zu reduzieren, indem es komplexe Anfragen durch die Synthese von Informationen aus vielfältigen Quellen beantwortet; und ebendies erfordert eine grundlegende Neubewertung bisheriger SEO-Taktiken.
Welche konkreten Auswirkungen diese tiefgreifenden Veränderungen auf die tägliche SEO-Arbeit haben und welche neuen Strategien erforderlich sind, um in dieser neuen Ära der Suche weiterhin Sichtbarkeit zu gewährleisten, wird ein kommender Artikel detailliert beleuchten.
Hinterlasse eine Antwort