Optimierung für AI Overviews und AI Mode ≠ SEO, oder?
Optimierung für AI Overviews und AI Mode ≠ SEO, oder? https://patrickstolp.de/wp-content/uploads/2025/05/ai-mode-llm-seo-e1748679467219.jpg 1012 717 Patrick Stolp https://secure.gravatar.com/avatar/6bdd2bf10b32556ccbe5a3b16931cb997c2c973524b74b20c375f7c9174c3ecd?s=96&d=blank&r=gViele SEOs flippen auf LinkedIn aktuell aus. Ausnahmsweise auch mit Recht, so meine Meinung. Mit dem Aufkommen von Googles AI Overviews und dem sich abzeichnenden, tiefergreifenden AI Mode sehen sich viele in der Branche mit einer Welle der Unsicherheit konfrontiert. Doch inmitten dieser Umwälzungen macht eine erstaunlich oft gehörte Phrase die Runde: „Das ist doch alles nur SEO.“ Eine Aussage, die nicht nur eine bemerkenswerte Simplifizierung darstellt, sondern auch von einer gefährlichen Fehleinschätzung der technologischen Realität zeugt. Ist es die typisch menschliche Verdrängung angesichts existenzieller Veränderungen, die hier spricht? Oder schlicht ein Mangel an tiefgreifender Auseinandersetzung mit der Funktionsweise von Large Language Models (LLMs) und den daraus resultierenden generativen Oberflächen?
Man könnte argumentieren, das Gehirn sei faul, auf Effizienz getrimmt und neige dazu, Probleme zu unterdrücken. Und ja, eine ganze Branche, deren Protagonisten ihre Positionierung an die drei Buchstaben S-E-O geknüpft haben, spürt dieser Tage ein deutliches Beben. Die Behauptung, die „SEO-Basics blieben dieselben“, mag beruhigend klingen, ist aber ein Trugschluss. Das weiß jeder, der sich intensiv mit den technischen Grundlagen der neuen „Suchsysteme“, den LLMs, beschäftigt. So wie ich.
Dieser Artikel wird argumentieren, dass die Optimierung für generative KI-Systeme wie Googles AI Overviews oder den in Patenten wie „Search with stateful chat“ skizzierten AI Mode weit mehr ist als eine bloße Erweiterung des bekannten SEO-Toolkits. Es geht um eine neue Disziplin – nennen wir sie Large Language Model Optimization (LLMO) oder Generative Engine Optimization (GEO) – die ein tiefes Verständnis der zugrundeliegenden Technologien, eine radikal andere Herangehensweise an Content und eine Neuausrichtung strategischer Ziele erfordert. Wer jetzt nicht bereit ist, die alten Denkmuster zu hinterfragen und sich den neuen Realitäten zu stellen, riskiert nicht nur den Anschluss zu verlieren, sondern in der informationsgetriebenen Welt von morgen unsichtbar zu werden.
Disruption in der Informationsverarbeitung: Warum AI Overviews, AI Mode und LLMs die SEO-Landkarte fundamental neu zeichnen
Wer auf der Suche nach Informationen war, der bediente sich in der Regel einer Google-Suche. Wenn wir ehrlich sind, beschreibt dieses Anliegen die Funktion der Suchmaschine Google aber nicht sonderlich präzise. Tatsächlich – mit Ausnahme von Google-Formaten wie die Featured Snippets – erhielten Nutzer von Google nach der Eingabe einer Suchanfrage aber keine direkte Antwort, also eine Information, sondern eine Liste an Dokumenten, die womöglich die Antwort auf eine Frage hatten.
Die Liste war dabei vorsortiert nach vermeintlicher Relevanz, inhaltlicher Qualität und Vertrauen zum Publisher. Die Informationen musste ein Nutzer aber dennoch selbst herausfiltern.
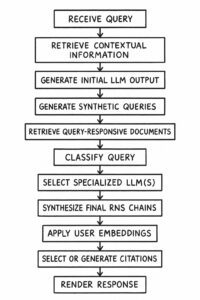
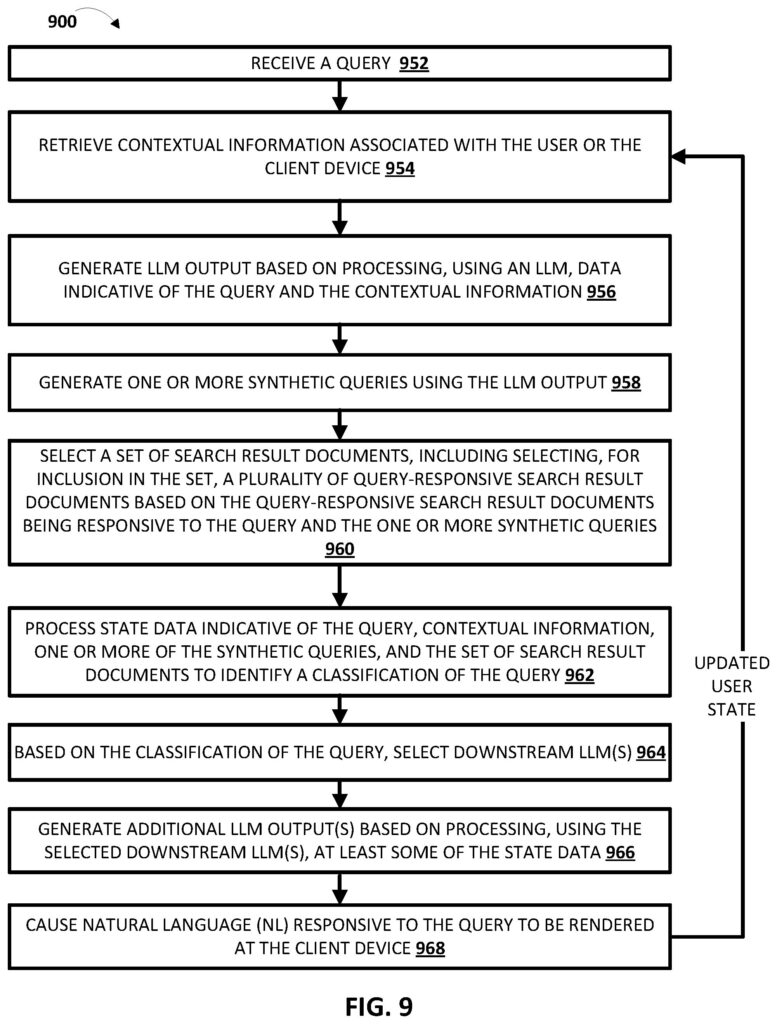
Dies ändert sich nun. Google übernimmt im AI Mode und teils auch durch die AI Overviews das Googeln für seine Nutzer. Der kognitive Aufwand wird für den Nutzer somit weiter gesenkt. Die Antwort auf die gestellte und mögliche Folgefragen gibt es jetzt direkt durch das Google-System, namentlich durch ein Query Fan-out.
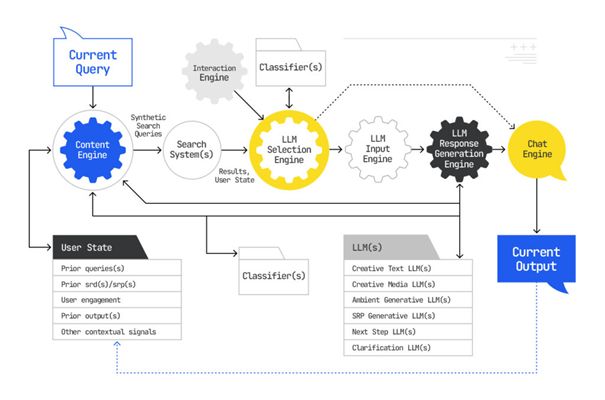
Der Google AI Mode geht über die explizite Suchanfrage hinaus. Basierend auf der initialen Suchanfrage können intern zusätzliche, „synthetische“ Suchanfragen generiert werden, um ein umfassenderes Verständnis zu erlangen und eine reichhaltigere Antwort zu erstellen. Eine erfolgreiche Optimierung muss daher nicht nur die primäre Anfrage, sondern auch diese impliziten, verwandten Fragen und ganze Nutzer-Journeys antizipieren und abdecken. Das Patent „Search with stateful cha“ beschreibt, wie der AI Mode hierfür einen „contextual search state“ über mehrere Interaktionen hinweg aufrechterhält. Mehr dazu unter Query Fan-Out in Google AI Mode: Definition & implizite SEO-Auswirkungen.
Googles erklärtes Ziel ist es, „das Googeln für dich zu erledigen“ und die kognitive Last für den Nutzer, die sogenannten „Delphic Costs“, zu reduzieren, indem das System die Informationssynthese übernimmt, die der Nutzer früher selbst leisten musste. Dies bedeutet, dass Inhalte nicht nur „gefunden“, sondern von der KI aktiv verarbeitet und weitergedacht werden.
Nicht nur der Google AI Mode, auch andere Sprachmodelle besitzen dafür „Reasoning“-Fähigkeiten, das heißt, sie können Informationen aus multiplen (oft heterogenen und multimodalen) Quellen nicht nur abrufen, sondern auch interpretieren, verknüpfen, bewerten und daraus neue Schlussfolgerungen oder komplexe Antworten synthetisieren.
Einzigartige Antworten durch Hyperpersonalisierung
Während Personalisierung in der Google-Suche nichts wirklich Neues ist, erreicht sie im AI Mode eine neue Dimension. Durch die Nutzung von User Embeddings, die einer AI-Mode-Konversation gewissermaßen als eine Art Layer überlagert und auf dem bisherigen Dialogverlauf (contextual state), dem Vorwissen des Nutzers zu bestimmten und potentiell Daten aus dem gesamten Google-Ökosystem (Gmail, Kalender etc.) basieren, wird jede Antwort hochgradig individualisiert.
Das Ideal eines für alle Nutzer gleichen Suchergebnisses, auf dem traditionelles Ranktracking beruht, löst sich damit für den AI Mode weitgehend auf. Die Konsequenz: Was für einen Nutzer eine relevante und hilfreiche Antwort darstellt, kann für einen anderen bei identischer Suchanfrage bereits ganz anders aussehen.
Large Language Models ranken und indizieren nicht
Wie bereits erwähnt steht das Ende der zehn blauen Links bevor. Es kommt die Zeit der personalisierten synthetisierten KI-Antworten. Im Zuge dessen möchte ich mit der häufig gelesenen Behauptung aufräumen, dass es für LLMs bzw. im AI Mode, bei ChatGPT und Co. „Rankingfaktoren“ gäbe. Große Sprachmodelle führen keine Ranking-Scorings durch, wie es Suchmaschinen tun.
Richtig ist zwar, dass einige LLMs und auch der Google-AI-Mode Retrieval-Techniken wie beispielsweise für das Grounding (eine Art Informationsfaktencheck durch Nutzung relevanter und vertrauenswürdiger Quellen) anwenden, allerdings ist dieser Prozess lediglich ein Mittel zum Zweck.
Die eigentliche Antwortgenerierung folgt dann LLM-internen Logiken der Wahrscheinlichkeitsberechnung und semantischen Kohärenz. LLMs haben auch keinen Dokumenten-Index im Sinne einer klassischen Suchmaschine; sie mögen zwar Vektordatenbanken nutzen, aber diese dienen ausschließlich der semantischen Ähnlichkeitssuche und nicht der Relevanzbewertung im Sinne klassischer Suchmaschinenrankings.
In einer Vektordatenbank werden Inhalte auf Basis ihrer Bedeutung als numerische Vektoren gespeichert, sodass ein LLM kontextuell passende Informationen abrufen kann. Entscheidend ist jedoch: Es findet keine Bewertung oder Gewichtung statt. Richtig ist zwar, dass mittlerweile auch die klassische Google-Suche mit Vektordatenbanken arbeitet, allerdings nur als Vorfiltrierung für weitere Bewertungssysteme wie das Qualitätssystem E-E-A-T.
Von SEO zu LLMO
Somit nähern wir uns einer zentralen Frage: Nämlich was der AI-Mode und grundlegende LLM-Techniken für die klassische Suchmaschinenoptimierung bedeutet. Es ist ein offenes Geheimnis, dass auch die klassische Google-Suche seit Hummingbird keine rein lexikalische Suche mehr ist, sondern eine hybride lexikalisch-semantische Suchmaschine.
Das bedeutet, dass auch im Google-Suchesystem teils noch Sparse-Retrieval-Methoden wie TF-IDF oder BM25 Anwendung finden, also klassische „Keyword“-Such-Systeme, beispielsweise um eine möglichst schnelle und kostengünstige Relevanzbewertung von Dokumenten bzw. Inhalten vornehmen zu können.
Vektorsysteme sind dann besonders nützlich, wenn nicht exakte Begriffsübereinstimmung, sondern semantische Nähe eine Rolle spielt – etwa bei der Suche nach ähnlichen Inhalten oder zur Identifikation thematisch verwandter Dokumente.
Nicht zu vergessen in Googles hauseigene Entitätendatenbank bzw. Entitäten-Index, der Knowledga Graph. Google nutzt heute hybride Rankingstrategien, um je nach Suchintention ein dynamisches Gleichgewicht zwischen Recall und Precision zu erzielen. Die Begriffe Recall und Precision stammen ursprünglich aus der Information Retrieval- und Suchmaschinentechnologie und sind zentrale Metriken zur Bewertung von Such- und Klassifikationssystemen.
Beide messen auf unterschiedliche Weise, wie gut ein System relevante Informationen identifiziert und ausliefert. Precision bevorzugt Qualität der Treffer. Recall bevorzugt Vollständigkeit der Treffer. Bei unklaren oder weit gefassten Suchanfragen wird Recall priorisiert (z. B. durch semantische Erweiterung via Entitäten oder Synonyme). Bei sehr konkreten oder transaktionalen Suchen hingegen fokussiert sich Google auf Precision, um dem Nutzer sofort die bestmögliche Antwort zu liefern.
Dieser hybride Ansatz der klassischen Google-Suche wird durch die Funktionsweise von LLMs und dem AI Mode nochmals auf eine neue Ebene gehoben, und zwar eine, die traditionelle Optimierungsansätze an ihre Grenzen bringt. Während die klassische Suche noch auf das Ranking von Dokumenten abzielt, auch wenn dies durch semantische Komponenten angereichert wird, geht es im AI Mode und bei LLM-generierten Antworten um die Synthese von Informationen aus den relevantesten Passagen oder „Chunks“ verschiedener Quellen.
Hier verschiebt sich der Fokus weg von der Optimierung eines gesamten Dokuments auf eine Handvoll Keywords hin zu einem deutlich granulareren und dynamischeren Prozess. Es geht nicht mehr primär darum, für Keywords zu ranken, sondern darum, die Wahrscheinlichkeit zu maximieren, dass die eigenen Inhalte (bzw. spezifische Abschnitte daraus) von einem LLM als die präzisesten, nützlichsten und vertrauenswürdigsten Informationsbausteine für die Beantwortung einer expliziten oder impliziten (synthetischen) Nutzeranfrage erachtet werden. Dies erfordert einen neuen Denkansatz: Relevanz-Engineering.
Relevanz-Engineering als neues Content-Optimierungsziel
Relevanz-Engineering zielt darauf ab, Inhalte auf die Verarbeitungslogik von Large Language Models zu optimieren. Im Kern geht es darum, Inhalte so zu strukturieren, zu formulieren und mit Kontext anzureichern, dass sie für LLMs optimal „lesbar“, interpretierbar und als Grundlage für die Antwortgenerierung geeignet sind. Doch was bedeutet das konkret?
Optimierung für LLM Readability und Chunk Relevance
LLMs, wie sie im AI Mode Anwendung finden, bevorzugen Inhalte, die klare Kontexte bieten, in natürlicher Sprache verfasst sind, eine logische Struktur und Informationshierarchie aufweisen und exakt auf die (oft sehr spezifische) Nutzerintention passen.
Dies bedeutet, Inhalte müssen in präzise, in sich geschlossene „Information Nuggets“ oder Chunks zerlegt werden können, die eine hohe semantische Dichte aufweisen und spezifische Aspekte einer Anfrage beantworten. Eine Studie zur Textvereinfachung (arXiv:2505.01980v1) unterstreicht, wie wichtig leicht verständliche und kognitiv wenig belastende Inhalte sind.
Antizipation synthetischer Queries und Nutzer-Journeys
Da der Google AI Mode basierend auf dem Nutzerkontext und der initialen Anfrage weitere, synthetische Queries generiert, reicht es nicht mehr, sich auf offensichtliche Keywords zu konzentrieren. Relevanz-Engineering muss darauf abzielen, komplette Themencluster und potenzielle Nutzer-Journeys so abzudecken, dass die eigenen Inhalte auch für diese impliziten Anfragen als relevant erkannt werden. Dies erfordert eine tiefere Auseinandersetzung mit einer Thematik und den möglichen Informationspfaden der Nutzer.
Nutzung von Vektor-Embeddings zur Analyse und Optimierung
Um die semantische Relevanz von Content-Passagen für spezifische (auch synthetische) Anfragen zu bewerten, müssen SEOs selbst Werkzeuge und Methoden der Vektorisierung und Ähnlichkeitsberechnung anwenden.
Es geht also darum, Vektor-Embeddings für Queries und Content-Passagen zu generieren (idealerweise mit Googles eigenen Modellen ), deren Ähnlichkeit zu berechnen (z.B. Kosinus-Ähnlichkeit) und auf dieser Basis die Inhalte gezielt semantisch anzureichern.
Grundsätzlich gilt zukünftig zu berücksichtigen, dass der Google AI Mode multimodal funktioniert, also nicht nur Text, sondern auch Bilder, Audio und Video berücksichtigt. Relevanz-Engineering muss daher auch die Optimierung und Bereitstellung dieser multimodalen Inhalte umfassen, um sicherzustellen, dass die eigenen Informationen in der für die jeweilige Anfrage und den Nutzerkontext am besten geeigneten Form berücksichtigt werden können.
Es bedarf neuer Metriken zur Erfolgsmessung
Die Rolle klassischer Suchmaschinen-Rankings als primärer Indikator für Sichtbarkeit und Erfolg erodiert im Kontext generativer KI-Systeme zusehends. Zum einen weil LLMs, wie erklärt, nicht ranken und es grundsätzlich personalisierte Antworten gibt. Sichtbarkeit zu messen, wird also nahezu unmöglich.
Zum anderen zeigen Analysen aktueller AI Overviews in den Google-Suchergebnissen bereits eine signifikante Diskrepanz: Die in den KI-generierten Antworten zitierten Quellen korrelieren immer weniger mit den Top-10-Positionen der traditionellen organischen Suchergebnisse. Es kommt vor, dass Quellen zitiert werden, die weit jenseits der Top-10 oder sogar außerhalb der Top-100 ranken. Ähnliche Muster sind auch bei anderen LLM-basierten Antwortsystemen wie ChatGPT zu beobachten. Es könnte sein, dass die Situation für den Google AI Mode nicht sonderlich anders sein wird.
Hinzu kommt, dass Unternehmen wie Deepseek oder Alibaba intensiv an Methoden forschen, um ihre LLMs für das Grounding weniger abhängig von externen Suchmaschinen zu machen. Die Gründe hierfür sind vielfältig: Kostenreduktion, größere Unabhängigkeit und potenziell schnellere Antwortgenerierung.
Sollten sich diese Ansätze durchsetzen, würde der Einfluss traditioneller Suchmaschinen-Rankings auf Erwähnungen von rankenden URLs in LLM-Antworten weiter signifikant sinken. Es ist daher riskant, sich als SEO darauf zu verlassen, dass gute Rankings in der klassischen Suche automatisch zu Sichtbarkeit in LLM-basierten Systemen führen.
Neue KPIs für das Zeitalter der KI-gestützten Suche
Wie Google selbst andeutet, sollen SEOs aufhören, primär Klicks zu messen. Googles AI Mode und ähnliche Systeme zielen wie aufgezeigt darauf ab, Nutzeranfragen direkt in der Suchoberfläche umfassend zu beantworten. Dies führt unweigerlich dazu, dass Nutzer seltener auf die zugrundeliegenden Quell-Websites klicken.
Sichtbarkeit bedeutet hier nicht mehr primär, Klicks auf die eigene Seite zu generieren, sondern als vertrauenswürdige Quelle in der generierten Antwort prominent zitiert oder referenziert zu werden. Dies wirft eine kritische Frage auf: Wenn traditionelle Indikatoren wie Position, Klicks oder Impressionen an Aussagekraft verlieren, wie messen wir dann zukünftig Erfolg?
Aus den bisherigen Ausführungen ergeben sich für mich folgende neue KPIs:
- Chunk Retrieval Frequency: Wie oft werden einzelne Inhalts-„Chunks“ abgerufen? Dies spiegelt die Relevanz auf granularer Ebene wider, die für LLM-Antworten entscheidend ist.
- Embedding Relevance Score: Die Vektorähnlichkeit zwischen Suchanfrage und Inhalt, beispielsweise durch Cosinus-Ähnlichkeit – ein Kernmaß für die Auffindbarkeit in Vektordatenbanken und somit ein Indikator für die semantische Passgenauigkeit.
- Attribution Rate in LLM Outputs / LLM Citation Count: Wie oft wird eine Marke oder Quelle in KI-generierten Antworten namentlich genannt oder zitiert? Dies wird zur neuen Währung für Sichtbarkeit und Vertrauen und zeigt den direkten Einfluss auf die Antwortgenerierung.
- Vector Index Presence Rate: Der Prozentsatz der eigenen Inhalte, der in relevanten Vektordatenbanken indexiert ist. Denn was nicht auffindbar ist, kann nicht Teil einer LLM-Antwort werden.
- LLM Answer Coverage: Die Anzahl unterschiedlicher Fragen und Themenbereiche, die durch die eigenen Inhalte abgedeckt und potentiell von einem LLM für Antworten genutzt werden können; ein Indikator für thematische Breite und Nützlichkeit.
Die unbequeme Wahrheit: Wer jetzt nicht handelt, wird Teil der digitalen Vergangenheit
Die Analyse ist eindeutig, die Schlussfolgerung unumgänglich: Die Optimierung für Googles AI Mode (und andere LLM-Systeme) ist nicht „nur SEO“. Wer dies weiterhin behauptet, verschließt die Augen vor einem Umbruch, der die Grundfesten unserer SEO-Branche erschüttert. Es geht hier nicht um ein weiteres Algorithmus-Update, das mit ein paar taktischen Anpassungen pariert werden kann. Wir erleben eine disruptive Veränderung in der Art und Weise, wie Nutzer Informationen suchen, erhalten und mit ihnen interagieren.
Der vielzitierte Ausruf „SEO ist tot“ mag in der Vergangenheit oft übertrieben gewesen sein – doch diesmal steht mehr auf dem Spiel als nur Rankingfaktoren. Es geht um die zukünftige Relevanz im digitalen Informationsraum.
Die Bequemlichkeit des Bekannten und die menschliche Neigung, komplexe Probleme zu verdrängen, mögen verständlich sein. Doch sie sind in der aktuellen Situation fatale Ratgeber. Die technologischen Realitäten erfordern ein radikales Umdenken. Wer sich jetzt nicht mit den technologischen Grundlagen von LLMs auseinandersetzt, wer nicht bereit ist, neue Kompetenzen aufzubauen, bestehende Werkzeuge kritisch zu hinterfragen und organisationale Silos einzureißen, der wird den Anschluss verlieren.
Die Zukunft der Informationsbeschaffung liegt im Dialog, in der direkten, KI-gestützten Bedürfnisbefriedigung. Wir müssen lernen, Inhalte für KI-Agenten aufzubereiten, die als Interpreten und Synthetisierer für den Endnutzer fungieren. Die Herausforderung liegt darin, die Informationsräume so zu gestalten, dass die probabilistischen Modelle der KI zu validen, hilfreichen und – aus Unternehmenssicht – förderlichen Ergebnissen „raten“.
Wie ich bereits an anderer Stelle formulierte: Ein Sprachmodell versteht nicht, weil es „weiß“, sondern weil es gut „rät“ – und das gelingt nur, wenn seine Wahrscheinlichkeitsverteilung die zugrundeliegende Realität approximiert.
Die Kunst für uns als Informationsarchitekten und Zukunftsgestalter im digitalen Raum wird sein, genau diese Approximation im Sinne unserer Ziele zu beeinflussen. Das ist die eigentliche Aufgabe jenseits von Keywords und Backlinks. Wer diese Herausforderung annimmt, hat die Chance, die nächste Ära des Search Marketings aktiv mitzugestalten. Wer sie ignoriert, wird unweigerlich Teil der digitalen Vergangenheit. Es gibt keine Ausreden mehr.