Wie du Auswirkungen eines Google Core Updates auf deine Website mit Keyword-Embeddings analysierst

Rankings schwanken nach jedem Core Update. Die erste Reaktion ist fast immer dieselbe: Ranking-Tracker öffnen, Klicks vergleichen, die Verluste beziffern. Welche Seiten haben verloren? Wie viele Positionen? Wie viel Traffic?
Das ist als operativer erster Schritt richtig. Aber er beantwortet eher eine Frage nach dem Was, nicht nach dem Wieso. Du weißt danach, dass du verloren hast und wo im Ranking. Du weißt nicht, was sich verändert hat — und vor allem nicht, ob die Klick-Verluste deiner Website einen einzigen Grund haben oder mehrere.
Die eigentliche Frage müsste daher lauten: Betrifft der Verlust mein gesamtes thematisches Profil — oder hat Google in spezifischen Themenfeldern die Quellenauswahl verschoben, während andere Bereiche stabil geblieben sind?
Das klingt nach einem eher rein erkenntnistheoretischem Unterschied. Tatsächlich hat die Antwort aber praktische Relvanz. Im ersten Fall müsstest du deine gesamte Content-Strategie überdenken. Im zweiten Fall musst du gezielt in den betroffenen Themenfeldern nachbessern. Wer das nicht unterscheidet, investiert Ressourcen an der falschen Stelle.
Dieser Artikel stellt eine Methodik vor, die genau diese Unterscheidung sichtbar macht — mit Mitteln, die jedem SEO zugänglich sind: Google-Search-Console-Daten und ein Embedding-Modell.
Was bei einem Core Update tatsächlich passiert
Negative Folgen für eine spezifische Website nach einem Core Update sind keine Strafe und keine manuelle Penalty-Maßnahme. Sie bedeuten nicht, dass deine Website gegen eine Richtlinie verstoßen hat. Das ist mittlerweile Konsens in der Branche — Google selbst betont es regelmäßig. Aber „keine Strafe“ beantwortet nicht die Frage, was stattdessen passiert. Und genau hier wird es in den meisten Analysen dünn.
Was tatsächlich passiert, ist eine Rekalibrierung der Signalgewichtung. Google verändert nicht die Signale selbst — PageRank, Nutzersignale, Content-Qualität bleiben als Kategorien bestehen. Was sich ändert, ist das Verhältnis, in dem diese Signale zueinander gewichtet werden. Ein Signal, das gestern 15% des Gesamtscores ausgemacht hat, macht morgen vielleicht 22% aus. Ein anderes fällt von 10% auf 6%. Die Signale bleiben, die Gewichte verschieben sich.
Das klingt abstrakt. Ist es auch — solange man nicht versteht, wie Google diese Signale überhaupt erzeugt. Denn die meisten SEOs sprechen von „Rankingfaktoren“, als wären es Schrauben, an denen Google dreht. In Wirklichkeit ist die Mechanik eine andere, und sie besteht aus vier Stufen.
Stufe 1: Menschen bewerten Seiten
Google beschäftigt tausende Quality Rater weltweit. Das sind reale Personen, die Webseiten nach den Search Quality Evaluator Guidelines bewerten. Sie beurteilen zum Beispiel und etwas abstrahiert: Hat der Autor nachweisbare Erfahrung? Ist die Seite vertrauenswürdig? Ist der Inhalt hilfreich? Diese Bewertungen sind qualitative Urteile — keine Scores, keine Zahlen. Und sie fließen nicht direkt ins Ranking ein. Kein Rater entscheidet, ob deine Seite auf Platz 3 oder Platz 30 steht. Aber sie dienen als Trainingsdaten für das, was in Stufe 2 passiert.
Wer die Search Quality Evaluator Guidelines kennt, dürfte sich an etwas erinnert fühlen, das wesentlich bekannter ist als die SQE-Guidelines: Was die Rater bewerten, ist im Kern Googles Qualitätskonzept E-E-A-T — Experience, Expertise, Authoritativeness, Trustworthiness. Google selbst betont, dass E-E-A-T kein Rankingfaktor ist und kein einzelner Score. Das stimmt — aber es ist auch nur die halbe Wahrheit. E-E-A-T ist das konzeptionelle Framework, das beschreibt, was Google unter Qualität versteht. Die Frage ist, wie dieses Konzept technisch operationalisiert wird. Denn die menschlichen Rater-Urteile müssen irgendwann in maschinell verwertbare Signale überführt werden — und genau das passiert in der nächsten Stufe.
Olaf Kopp — einer der wenigen deutschen SEOs, die sich systematisch mit den Patenten und Forschungsarbeiten hinter E-E-A-T auseinandersetzen — hat die Verbindung zwischen dem menschlichen Konzept und der technischen Implementierung detailliert aufgearbeitet. Er unterscheidet drei Bewertungsebenen: Dokumentenebene (Content-Qualität des einzelnen Beitrags), Domainebene (Site-weite Qualität und thematische Autorität) und Source-Entity-Ebene (Reputation des Autors oder der Organisation als Entität). Auf jeder dieser Ebenen existieren eigene Signale, die in Qualitätsklassifikationen einfließen.
Dass Google auf allen drei Ebenen bewertet, ist ein wichtiger Punkt für das Verständnis von Core Updates. Denn es erklärt, warum ein Update eine Website in einem Themenfeld treffen kann und in einem anderen nicht: Die Signale auf Dokumentenebene können für verschiedene Dokumente derselben Domain völlig unterschiedlich ausfallen. Ein starker Fachartikel mit eigenen Daten und ein dünner Ratgeber-Text stehen auf derselben Domain, werden aber auf Dokumentenebene fundamental anders bewertet.
Stufe 2: Machine-Learning-Modelle lernen Muster
Google trainiert mit diesen Rater-Bewertungen Classifier — Machine-Learning-Modelle, die lernen, welche messbaren Eigenschaften einer Seite mit dem Urteil „hohe Qualität“ korrelieren. Der Classifier lernt dabei nicht „Autorenexpertise“ als abstraktes Konzept. Er lernt messbare Stellvertreter-Merkmale — also Eigenschaften einer Seite, die sich technisch erfassen lassen und die statistisch mit hohen Rater-Bewertungen zusammenhängen. Nicht „Expertise“ selbst, sondern das, was Expertise hinterlässt, wenn sie auf einer Webseite stattfindet.
Aus dem Google Content Warehouse API-Leak von 2024 kennen wir einige dieser Stellvertreter-Merkmale konkret. Eine Anmerkung zur Quellenlage: Google hat die Authentizität der geleakten Dokumente bestätigt, gleichzeitig aber darauf hingewiesen, dass die Dokumente ohne Kontext über die tatsächliche Verwendung im Live-Ranking gelesen werden müssen. Die Attribute existieren — wie sie gewichtet werden, ist nicht dokumentiert.
| Beispiel-Signale aus dem API-Leak | Was das Signal misst |
|---|---|
contentEffort | LLM-basierte Einschätzung des qualitativen Aufwands eines Inhalts |
OriginalContentScore | Einzigartigkeit des Inhalts (Skala 0–512) |
authorReputationScore | Reputation auf Autorenebene |
siteAuthority | Autorität auf Site-Level — deren Existenz Google jahrelang bestritten hat |
isAuthor | Ob überhaupt ein identifizierbarer Autor zugeordnet ist |
Keines dieser Signale misst direkt, ob ein Autor Medizin studiert hat oder zwanzig Jahre Berufserfahrung mitbringt. Was sie messen, sind Muster — messbare Spuren, die Qualität auf einer Webseite manifestieren.
Ein Beispiel: Seiten mit identifizierbaren Autoren, die auch auf anderen autoritativen Seiten publizieren, bekommen von Ratern tendenziell höhere Bewertungen. Das Modell lernt diesen Zusammenhang und bildet ihn im authorReputationScore ab — ohne zu verstehen, was Expertise ist.
Ein zweites Beispiel: Eine Seite mit selbst erstellten Diagrammen, eigenen Vergleichstabellen und einem eingebetteten Rechner bekommt von Ratern höhere Bewertungen als eine Seite, die dasselbe Thema als reinen Fließtext behandelt. Das Modell lernt: Seiten mit vielfältigen, eigenständig erstellten Inhaltselementen korrelieren mit dem Urteil „hoher Aufwand“. Das ist, was contentEffort erfasst — nicht die Wörterzahl, sondern die „Spuren“ von Arbeit, die im Inhalt sichtbar sind.
Ein drittes Beispiel: Ein Text, der einen Sachverhalt mit eigenen Daten, eigenen Fallbeispielen und einer eigenen Einordnung darstellt, wird von Ratern höher bewertet als ein Text, der denselben Sachverhalt so wiedergibt, wie er auf fünfzig anderen Seiten formuliert ist. Das Modell lernt: Textuelle Einzigartigkeit korreliert mit Qualität. Das bildet OriginalContentScore ab — auf einer Skala von 0 bis 512.
Das Prinzip ist immer dasselbe: Das Modell misst nicht das abstrakte Konzept. Es misst die Spuren, die das Konzept auf einer Webseite hinterlässt. Und diese Spuren sind technisch erfassbar.
Entscheidend ist, was am Ende dieser Stufe steht: eine maschinelle Bewertung pro Dokument. Kim beschreibt im DOJ-Verfahren, dass Googles Ingenieure Sigmoid-Funktionen nutzen, um aus Daten Schwellenwerte abzuleiten — das deutet auf numerische Werte hin, die intern berechnet und anschließend in Qualitätsstufen eingeteilt werden. Die konkreten Werte und Stufen sind nicht öffentlich. Was wir wissen: Diese Bewertungen fließen als Eingabe in den aggregierten Q*-Score in Stufe 3 ein.
Stufe 3: Einzelscores werden zu Q* aggregiert
Q* ist, soweit sich das aus den DOJ-Dokumenten und dem API-Leak rekonstruieren lässt, ein aggregierter Qualitätsscore pro Dokument. Kim beschreibt als Eingangssignale unter anderem: PageRank — von ihm definiert als „Distanz zu einer bekannten vertrauenswürdigen Quelle“ —, den Spam-Score und die Ergebnisse der quality-rater-basierten Qualitätsbewertung aus Stufe 2.
Hyung-Jin Kim, VP of Engineering (Search) bei Google, hat im DOJ-Verfahren unter Eid ausgesagt: „Q* — page quality, also die Idee von Vertrauenswürdigkeit — ist unglaublich wichtig.“ Er ergänzte: „Seitenqualität ist das, worüber sich die Leute am meisten beschweren.“ Und: „KI macht es noch schlimmer.“ — eine Einordnung, die zeigt, dass Google das eigene Qualitätsproblem im Kontext generativer Inhalte durchaus sieht. Aber das nur nebenbei.
Stufe 4: Der Score trifft auf Schwellenwerte
Dass Google intern mit Schwellenwerten arbeitet, geht aus den DOJ-Dokumenten hervor — Kim spricht von „curves and thresholds“. Diese Schwellenwerte sind technisch gesehen Classifier-Grenzen: Sie trennen Dokumente in Qualitätsklassen — etwa „qualifiziert für diesen Ranking-Pool“ oder „nicht qualifiziert“. Das ist keine Punktevergabe auf einer Skala, sondern eine Einordnung: drin oder draußen.
Shaun Anderson hat über seine Datenanalyse des API-Leaks beobachtet, dass Websites mit einem Q*-Score unter 0,4 nicht für Featured Snippets und People-Also-Ask-Boxen berücksichtigt werden — ein Beispiel für einen solchen binären Classifier-Schwellenwert.
Was das für Core Updates bedeutet
Wenn ein Core Update die Gewichtung der Signale verändert — sei es in der Q*-Berechnung, in den Classifiern, die darüber entscheiden, ob ein Dokument überhaupt in den Ranking-Pool kommt, oder in den Twiddlern, die danach nachjustieren —, dann verändert sich die Bewertung eines Dokuments, ohne dass sich am Content etwas geändert hat.
Dieselbe Seite, derselbe Autor, derselbe Text. Aber der resultierende Score rutscht unter einen Schwellenwert, der vorher noch überschritten wurde.
Und hier wird es für die Analyse entscheidend: Verschiedene Themenfelder gewichten verschiedene Signale unterschiedlich. Eine Suchanfrage zu Gesundheitsthemen gewichtet Autorenexpertise anders als eine Suchanfrage zu Produktvergleichen. Das bedeutet, dass eine Schwellenwertverschiebung nicht die gesamte Website gleich trifft — sondern themenspezifisch wirkt.
Ein konkretes Beispiel. Stell dir einen Onlineshop für Laufschuhe vor, der in drei Themenfeldern rankt: Laufschuh-Tests, Gesundheitsratgeber zum Thema Laufen, und Kaufberatung. Ein Core Update gewichtet authorReputationScore für gesundheitsnahe Queries stärker. Der Shop-Redakteur hat keinen messbaren Reputation-Score im Gesundheitsbereich — sein Q*-Score für die Gesundheitsartikel rutscht unter den Schwellenwert. Seine Laufschuh-Tests bleiben stabil, weil dort andere Signale dominieren: originale Produktfotos, Vergleichsdaten, OriginalContentScore. Im Ranking-Tracker sieht der Betreiber „20% Traffic verloren“. Was er nicht sieht: Die Verluste konzentrieren sich in einem spezifischen Themenfeld — und die stabilen Bereiche sind aus anderen Gründen stabil.
Genau diese Unterscheidung — welche Themenfelder betroffen sind und welche nicht — ist das, was eine herkömmliche Ranking-Analyse nicht liefert. Und das, was eine semantische Analyse sichtbar machen kann.
Google denkt in Vektoren — und das lässt sich nutzen
Was im vorherigen Abschnitt beschrieben ist — themenspezifische Schwellenwertverschiebungen, die verschiedene Bereiche einer Website unterschiedlich treffen —, ist konzeptionell nachvollziehbar. Aber es wirft eine praktische Frage auf: Wie macht man das sichtbar?
Wer meine Artikelreihe zur KI-Suche gelesen hat, kennt das Prinzip: Moderne Suchmaschinen — und KI-Chatbots — arbeiten nicht mit Wörtern, sondern mit Vektoren. Jeder Text, jede Suchanfrage, jedes Dokument wird in eine Zahlenreihe umgewandelt, die seine semantische Position in einem hochdimensionalen Bedeutungsraum beschreibt. Keywords mit ähnlicher Bedeutung liegen in diesem Raum nah beieinander — unabhängig von der exakten Formulierung. „Knieschmerzen beim Joggen“ und „Läuferknie Ursachen“ liegen nah beieinander. „Laufschuh Dämpfung Test“ liegt deutlich weiter entfernt — obwohl alle drei mit dem Oberthema Laufen zu tun haben.
Dass Google selbst in genau solchen Vektoren denkt — nicht nur bei Suchanfragen und Dokumenten, sondern auch bei der Bewertung ganzer Websites —, ist keine Spekulation. Das Patent US20200050707A1 („Website Representation Vector“, Google LLC, 2018) beschreibt explizit, wie Google Vektoren für Websites berechnet. Es beschreibt, wie Zentroiden für Qualitätsklassen gebildet werden: ein Durchschnittsvektor für niedrige Qualität, ein anderer für hohe Qualität. Und es beschreibt, wie neue Websites über ihren Abstand zu diesen Zentroiden klassifiziert werden.
Das Patent wurde vom Anmelder aufgegeben und ist nicht notwendigerweise implementiert. Aber die Denkrichtung ist aufschlussreich: Google modelliert Websites als Positionen in einem Vektorraum und bewertet sie über Abstände zu Referenzpunkten. Das ist exakt das Prinzip, das sich für die Analyse von Core-Update-Auswirkungen nutzen lässt.
Die Idee ist einfach: Wenn wir die Keywords, für die eine Website rankt, in einen Vektorraum projizieren, erhalten wir ein semantisches Profil dieser Website — eine Karte dessen, wofür die Website in der organischen Suche sichtbar ist. Wenn wir das für zwei Zeiträume tun — vor und nach einem Core Update — und die beiden Karten übereinanderlegen, können wir sehen, ob und wo sich dieses Profil verschoben hat. Nicht auf der Ebene einzelner Rankings, sondern auf der Ebene thematischer Cluster.
Die Methode
Die praktische Umsetzung besteht aus fünf Schritten.
Schritt 1: Zwei Keyword-Sets aus der Google Search Console exportieren
Du brauchst die Suchanfragen für zwei klar abgegrenzte Zeiträume — einen stabilen Zeitraum vor dem Core Update und einen stabilen Zeitraum nach dem vollständigen Rollout. Beide Zeiträume sollten gleich lang sein, mindestens 28 Tage, und nicht durch andere Ereignisse kontaminiert — keine technischen Relaunches, keine saisonalen Ausreißer, keine überlappenden Update-Rollouts.
Die gleiche Fensterlänge ist wichtig: Die Search Console summiert Klicks und Impressionen über den gewählten Zeitraum auf, ohne sie auf einen Tagesdurchschnitt umzurechnen. Wer 60 Tage gegen 28 Tage vergleicht, vergleicht nicht zwei gleichwertige Messungen, sondern eine große Zahl mit einer kleinen — und zieht daraus falsche Schlüsse.
Schritt 2: Keywords in Vektoren umwandeln
In dieser Analyse verwende ich paraphrase-multilingual-mpnet-base-v2 — ein multilinguales Embedding-Modell, das für deutschsprachige Keywords gut kalibriert ist und direkt in Google Colab läuft, ohne externen API-Zugang.
Schritt 3: Den semantischen Mittelpunkt pro Zeitraum berechnen
Für jede Periode wird der Zentroid berechnet — der Durchschnittsvektor aller Keywords in diesem Zeitraum. Der Zentroid repräsentiert den semantischen Schwerpunkt des gesamten Keyword-Profils. Bildlich: der Punkt im Bedeutungsraum, um den herum sich die rankenden Keywords gruppieren.
Schritt 4: Den Abstand zwischen den beiden Mittelpunkten messen
Zwischen den beiden Zentroiden wird die Kosinus-Distanz gemessen — ein Distanzmaß, das aus der Kosinus-Ähnlichkeit abgeleitet wird und den Winkel zwischen zwei Vektoren in eine Entfernung übersetzt. Ein Wert nahe null bedeutet: Der thematische Schwerpunkt ist nahezu identisch geblieben. Ein deutlich höherer Wert deutet auf eine messbare Verschiebung hin.
Schritt 5: Visualisieren
Die hochdimensionalen Vektoren werden über eine Dimensionsreduktion auf zwei Achsen heruntergerechnet, sodass sie sich als Punkte auf einer Fläche darstellen lassen. Jedes Keyword wird ein Punkt:
| Farbe | Bedeutung |
|---|---|
| Blau | Keywords, die im Zeitraum vor dem Update rankten, danach nicht mehr — verloren |
| Orange | Keywords, die nur nach dem Update auftauchen — neu gewonnen |
| Grün | Keywords, die in beiden Perioden vertreten sind — stabil |
Die Größe jedes Punkts spiegelt das Klickvolumen wider. Das Ergebnis ist eine Karte — keine Ranking-Tabelle, sondern eine visuelle Darstellung der thematischen Struktur deines Keyword-Profils und der Verschiebungen, die das Core Update darin verursacht hat.
Die gesamte Analyse läuft über ein Python-Notebook in Google Colab. Keine lokale Installation, zwei CSV-Exporte aus der Search Console reichen aus — das Embedding-Modell läuft direkt im Notebook, ohne externen API-Key.
Anmerkung zur Entstehung dieser Analyse
Die Grundidee, GSC-Keyword-Sets über Text-Embeddings zu visualisieren, stammt nicht von mir. Dan Hinckley hat diese Methode in einem LinkedIn-Post vorgestellt. Was mich daran interessiert hat, war nicht die technische Basis, sondern die Frage, die sie beantworten kann: Lässt sich damit sichtbar machen, was bei einem Core Update auf der semantischen Ebene passiert?
Das Notebook selbst habe ich nicht programmiert. Ich bin SEO-Stratege, kein Entwickler. Die technische Implementierung habe ich mithilfe von generativer KI erstellt. Was ich beurteilen kann, ist die konzeptionelle Logik: welche Daten eingehen, was die Berechnungen bedeuten, wie die Ergebnisse zu interpretieren sind — und vor allem, wie sie sich in das einfügen, was wir über Googles Ranking-Architektur aus den DOJ-Dokumenten und dem API-Leak wissen. Das ist mein Beitrag zu dieser Methode.
Was ich gefunden habe
Für den Test dieser Methode habe ich eine Website aus dem E-Commerce analysiert — ein Online-Shop, das rund um Tabakprodukte rankt. Der Vergleichszeitraum: Oktober bis Dezember 2025 (vor dem Core Update im Dezember 2025) gegen Januar bis Februar 2026 (nach dem vollständigen Rollout).
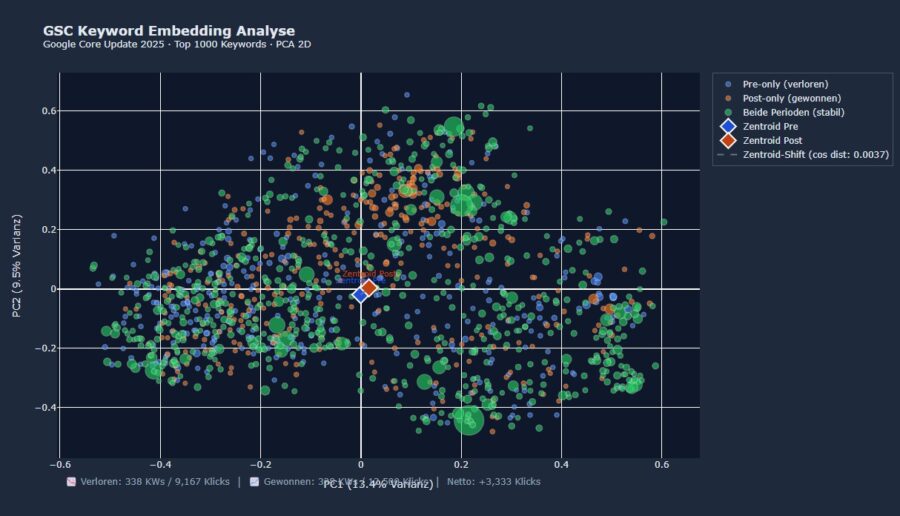
Das Ergebnis auf den ersten Blick: Insgesamt 338 Keywords aus den Top-1.000 gingen verloren, 338 neue kamen hinzu. Die Zentroid-Distanz beträgt 0,0037 — praktisch null. Der thematische Schwerpunkt hat sich nicht verschoben.
Aber die interessantere Frage ist: Was verbirgt sich hinter dem Keyword-Turnover? Wenn 338 Keywords verschwinden und 338 neue auftauchen, könnte das eine thematische Verschiebung sein — bestimmte Themenfelder verloren, andere gewonnen. Genau das soll die Visualisierung ja auch sichtbar machen.
In diesem Fall zeigt sie etwas anderes. Die verlorenen Keywords (blau) und die gewonnenen Keywords (orange) liegen nicht in verschiedenen Regionen des Vektorraums. Sie liegen übereinander — in denselben semantischen Clustern. Der Grund wird sichtbar, wenn man sich die konkreten Keywords anschaut:
| Verloren (Beispiele) | Gewonnen (Beispiele) |
|---|---|
| gratis tabak dose 2025 | gratis tabak dose 2026 |
| iqos adventskalender | gratis zigaretten aktuell 2026 |
| zigaretten adventskalender | code für gratis zigaretten 2026 |
| benson & hedges tabak gratis | gratis zigaretten 2026 |
Das ist keine thematische Verschiebung. Das ist temporaler Keyword-Turnover — Suchanfragen, die an ein Kalenderjahr oder an zeitlich befristete Aktionen gebunden sind und sich natürlicherweise von 2025 auf 2026 verschieben. Die Website rankt für die neuen Jahresvarianten genauso wie für die alten. Die Netto-Bilanz ist sogar positiv: +3.333 Klicks. Die Site hat im Kontext des Dezember Core Updates keine thematischen Verluste erlitten.
Warum der Test trotzdem ein wichtiges Ergebnis ist
Ein Online-Shop-Besitzer oder SEO, der nur auf die Ranking-Tabelle schaut, sieht: 338 Keywords verloren. Das klingt nach einem Problem. Prüft dieser zusätzlich die Klickbilanz, sieht er: Netto-Klick-Gewinn. Das klingt nach Entwarnung. Aber weder die Tabelle noch die Bilanz beantwortet die diagnostische Frage: Hat sich etwas am thematischen Profil geändert?
Die Embedding-Analyse beantwortet sie: Nein. Verluste und Gewinne liegen in denselben semantischen Regionen. Es gibt kein Cluster, das einseitig betroffen ist. Die Ursache ist temporal, nicht qualitätsbedingt.
Das ist eine analytisch wertvolle Erkenntnis, denn sie verhindert eine Fehldiagnose. Wer in diesem Fall anfängt, Content zu überarbeiten oder andere zeitraubende SEO-Maßnahmen umsetzt, investiert Ressourcen in ein Problem, das nicht existiert.
Zentroiden-Stabilität ist nicht thematische Stabilität
Das ist der konzeptuell wichtigste Punkt dieser Methode. Ein stabiler Zentroid — also ein Gesamtschwerpunkt, der sich zwischen den beiden Zeiträumen kaum verschoben hat — bedeutet: Die durchschnittliche semantische Position der rankenden Keywords ist nahezu gleich geblieben. Das klingt zunächst beruhigend. Google scheint das thematische Profil der Website nicht grundsätzlich anders zu bewerten als vorher.
Aber der Durchschnitt kann täuschen. Stell dir einen Raum vor, in dem hundert Personen stehen — gleichmäßig verteilt. Wenn jetzt auf der linken Seite zehn Personen den Raum verlassen und auf der rechten Seite zehn neue dazukommen, verschiebt sich der Mittelpunkt kaum. Aber die linke Seite des Raums ist dünner besetzt als vorher, die rechte voller. Wer nur den Mittelpunkt betrachtet, bemerkt davon nichts.
Genau das passiert bei Core Updates. Der Gesamtschwerpunkt bleibt stabil, weil sich Verluste in einem Themenfeld und Gewinne in einem anderen gegenseitig ausgleichen. Aber innerhalb einzelner Cluster hat sich die Zusammensetzung verschoben. Die Visualisierung macht genau das sichtbar: Wo blaue Punkte — verlorene Keywords — nicht zufällig verteilt sind, sondern sich in bestimmten Regionen des Vektorraums konzentrieren, ist das ein thematisch konzentrierter Verlust. Kein Rauschen, sondern ein Muster.
Die Tabak-Shop-Analyse illustriert genau das: Der Zentroid blieb stabil (0,0037), 338 Keywords wurden ausgetauscht — und trotzdem war kein Themenfeld betroffen. Verluste und Gewinne lagen in denselben Regionen. Hätte die Methode stattdessen gezeigt, dass die blauen Punkte in einer bestimmten Ecke des Vektorraums clustern, wäre das ein Muster gewesen, das auf eine themenspezifische Schwellenwertverschiebung hindeutet.
Koray Tugberk Güler hat für dieses Phänomen einen nützlichen Interpretationsrahmen entwickelt: das Konzept der Quality Thresholds. Seine These: Für jedes Themenfeld existiert ein Qualitätsschwellenwert, den eine Website überschreiten muss, um für dieses Themenfeld kompetitiv zu ranken. Bei einem Core Update verschieben sich diese Schwellenwerte — aber nicht einheitlich. In einem Themenfeld steigt die Messlatte, in einem anderen bleibt sie gleich, in einem dritten sinkt sie vielleicht sogar. Google bewertet nicht die gesamte Website pauschal um, sondern rekalibriert die Schwellenwerte pro Themencluster.
Das ist konzeptuell eine Synthese aus dem, was die harten Quellen einzeln belegen: Die DOJ-Dokumente bestätigen, dass Google intern mit „curves and thresholds“ arbeitet. Der API-Leak zeigt, dass der Q*-Score pro Dokument berechnet wird und dass verschiedene Signale auf verschiedenen Ebenen einfließen. Andersons Analyse zeigt einen konkreten Schwellenwert — unter Q* 0,4 keine Featured Snippets. Und der breite Konsens in der Branche ist, dass Core Updates themenspezifisch wirken, nicht pauschal. Korays Beitrag ist, diese Einzelbefunde zu einem operativen Denkmodell zusammenzuführen. Bewiesen als geschlossenes System ist es nicht — aber es ist eine der plausibelsten Erklärungen dafür, warum ein Core Update eine Website in einem Themenfeld treffen kann und in einem anderen verschonen.
Für die Praxis bedeutet das: Wer nach einem Core Update den Zentroid betrachtet und „kaum Veränderung“ sieht, ist nicht fertig mit der Analyse. Er hat gerade erst angefangen. Die eigentliche Frage lautet: In welchen Clustern liegen die Verluste — und was unterscheidet diese Cluster von den stabilen Bereichen? Erst diese Frage führt zu operativen Entscheidungen: Wo fehlt es an inhaltlicher Tiefe? Welche Themenfelder brauchen stärkere Autorensignale? Wo hat sich möglicherweise die Suchintention verschoben, sodass ein anderer Seitentyp gefragt ist? Die Gründe können verschieden sein.
Der Unterschied zwischen „meine gesamte Content-Strategie überdenken“ und „gezielt die betroffenen Themencluster stärken“ — das ist der Unterschied, den diese Analyse liefert.
Was diese Methode kann — und was nicht
Jede Methode hat Grenzen, und diese hier hat mehrere, die man kennen sollte.
Sie zeigt wo, nicht warum
Die Visualisierung macht thematische Verlustmuster sichtbar. Aber sie erklärt nicht, aus welchem Grund ein bestimmtes Cluster betroffen ist. Glenn Gabe — einer der erfahrensten Analysten für Core-Update-Auswirkungen — unterscheidet drei grundsätzlich verschiedene Gründe für Ranking-Drops nach Core Updates:
| Grund | Was passiert | Was du tun kannst |
|---|---|---|
| Relevanzverschiebung | Der Inhalt passt nicht mehr so gut zur Query wie vorher | Content überarbeiten, thematische Tiefe erhöhen |
| Intent Shift | Google rankt für dieselbe Suchanfrage jetzt einen anderen Seitentyp | Prüfen, ob ein anderer Seitentyp benötigt wird |
| Qualitätsproblem | Der Inhalt erfüllt die angehobenen Qualitätsanforderungen nicht mehr | Originalität und Tiefe stärken |
In der Praxis überlappen sich diese Kategorien — ein Intent Shift führt oft dazu, dass bestehender Content als weniger relevant bewertet wird. Alle drei Gründe können in derselben Visualisierung als blaues Cluster erscheinen. Die Embedding-Analyse sagt dir, dass eine Gruppe verlorener Keywords thematisch zusammengehört. Sie sagt dir nicht, ob das ein Relevanzproblem, ein Intent-Problem oder ein Qualitätsproblem ist. Diese Unterscheidung erfordert einen zweiten Schritt: die betroffenen Keywords manuell in den SERPs prüfen. Welche Seiten ranken jetzt stattdessen? Sind es andere Seitentypen? Oder inhaltlich tiefere Beiträge?
Die Visualisierung ist eine Projektion, kein Abbild
Um hochdimensionale Vektoren auf einer zweidimensionalen Fläche darzustellen, wird eine Dimensionsreduktion durchgeführt. Wie das genau funktioniert? Keine Ahnung, dafür gibt es generative KI. Was ich weiß: Das ist ein bewusster Informationsverlust. Cluster, die in zwei Dimensionen getrennt erscheinen, können im hochdimensionalen Raum näher beieinander liegen — und umgekehrt. Die 2D-Darstellung ist eine Arbeitshypothese, die Muster sichtbar macht. Sie ist kein maßstabsgetreuer Grundriss des Vektorraums.
Sprachliche Bedeutung ist nicht Googles Query-Semantik
Das ist eine wichtige Einschränkung. Wenn wir Keywords mit einem Embedding-Modell vektorisieren, nutzt das Modell sprachliche Bedeutungsnähe — gelernt aus großen Textmengen. Es weiß, dass „Knieschmerzen beim Joggen“ und „Läuferknie Ursachen“ thematisch zusammengehören, weil sie in ähnlichen sprachlichen Kontexten vorkommen.
Was das Modell nicht weiß, ist, wie Nutzer sich bei diesen Suchanfragen tatsächlich verhalten. Googles eigenes Verständnis von Query-Bedeutung ist verhaltensbasiert — es lernt aus Klickmustern, Session-Daten, NavBoost. Wenn Millionen Nutzer bei einer bestimmten Suchanfrage systematisch auf ein unerwartetes Ergebnis klicken, verschiebt sich für Google die Bedeutung dieser Query. Unser Embedding-Modell hat keinen Zugang zu diesen Verhaltensdaten.
Für die Aufgabe, thematische Cluster in einem Keyword-Set zu identifizieren, ist das kein Problem — dafür reicht sprachliche Bedeutungsnähe. Für die Frage, warum Google ein bestimmtes Keyword nach dem Update anders bewertet, reicht es nicht. Die Methode liefert die thematische Landkarte. Die Interpretation, was in den einzelnen Regionen dieser Landkarte passiert ist, bleibt menschliche Arbeit.
Sie ist kein Monitoring-Tool
Die Analyse funktioniert als Diagnoseinstrument nach einem Core Update, nicht als laufendes Monitoring. Sie vergleicht zwei Zeitpunkte miteinander und macht die Verschiebung dazwischen sichtbar. Wer laufend überwachen will, ob sich das thematische Profil verschiebt, braucht ein anderes Setup.
Fazit
Core Updates sind weniger Black Box, als viele annehmen. Sie sind komplex, aber ihre Mechanik lässt sich nachvollziehen — von den Quality-Rater-Bewertungen über die Classifier bis zum Q*-Score und den Schwellenwerten, die sich mit jedem Update verschieben. Wer diese Kette versteht, analysiert ein Core Update als Rekalibrierung mit nachvollziehbarer Logik.
Die hier vorgestellte Methode macht einen spezifischen Aspekt dieser Rekalibrierung sichtbar: die thematische Struktur der Verluste. Sie beantwortet nicht alle Fragen. Aber sie beantwortet die eine Frage, die den Unterschied macht zwischen einer Panikreaktion und einer gezielten Gegenmaßnahme: Betrifft der Verlust mein gesamtes thematisches Profil oder spezifische Cluster, die ich identifizieren und gezielt stärken kann?
Wer es selbst ausprobieren will oder seine GSC-Daten analysieren lassen möchte, kann mich gerne kontaktieren.
Über diesen Artikel
Die inhaltliche Verantwortung für jeden Artikel auf diesem Blog liegt bei mir, Patrick Stolp. Thema, These, Recherche und fachliche Prüfung sind meine Arbeit – hier wird nichts veröffentlicht, das ich nicht selbst konzipiert, geschrieben und als korrekt verifiziert habe. Generative KI (Claude von Anthropic) kommt punktuell als Werkzeug zum Einsatz – etwa für Formulierungsentwürfe oder das Gegenlesen technischer Erklärungen. Kein KI-Output landet ungeprüft oder unverändert auf dieser Seite. Beitragsbilder werden mit Google Nano Banana 2 erstellt.
Mehr dazu in meinen Redaktionsrichtlinien.