GEO ist das neue SEO ist GEO? Ja, was denn nun?

GEO ist das neue SEO. Jedenfalls wenn man der Branche zuhört. Plötzlich gibt es eigene Teams dafür, eigene Budgets, eigene Agenturen. Und natürlich eigene Konferenzen. Generative Engine Optimization klingt auch einfach besser als das, was es in vielen Fällen tatsächlich ist: semantische Suchmaschinenoptimierung, die man seit 2018 hätte machen sollen.
Ich habe in den vergangenen Monaten eine klare Position dazu vertreten. GEO ist eine Teilmenge von SEO. Wer semantisch optimiert, macht seit Jahren das, was heute unter diesem neuen Label verkauft wird. Die Technik ist nicht neu. Wer sie als eigene Disziplin verkauft, sollte überzeugend erklären können, was daran tatsächlich anders ist. Diese Position halte ich im Kern weiterhin für richtig.
Aber sie war an einer Stelle zu sauber.
Ich habe den Unterschied zwischen SEO und GEO auf einen einzigen Punkt reduziert: den Faktor Mensch. Nutzersignale, Klickverhalten, visuelle Psychologie. Alles, was in der klassischen Suche zählt, aber für einen KI-Chatbot ohne Browser irrelevant ist. Daraus habe ich geschlossen: Wenn man den Faktor Mensch aus SEO herausrechnet, bleibt GEO übrig.
Klingt elegant. Stimmt aber so nicht. Denn Analysen aus 2025 und 2026 zeigen, dass Klicksignale über Umwege auch in KI-Antworten landen. Und dass Google mit AI Mode gerade ein System baut, in dem die Unterscheidung zwischen „klassischer Suche“ und „KI-Suche“ technisch aufhört zu existieren.
Ich korrigiere meine Position deshalb an dieser Stelle. Nicht grundsätzlich, aber an einem wichtigen Punkt. Wer in einem Feld arbeitet, das sich in Echtzeit verändert, darf das tun. Solange er sagt, warum. Genau darum soll es im Folgenden gehen.
Was hinter dem neuen Etikett „GEO“ steckt: Information Retrieval
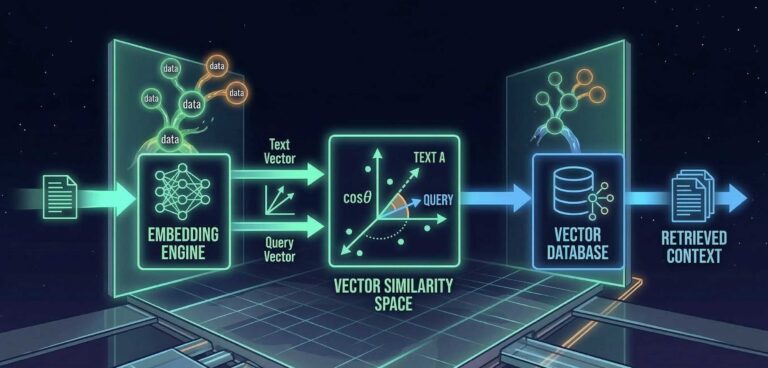
Das Verfahren, das die GEO-Debatte ins Zentrum rückt, heißt Retrieval Augmented Generation, kurz RAG. Es besteht aus zwei Stufen:
- Zuerst werden aus einer Datenquelle die relevantesten Textpassagen zu einer Frage herausgesucht.
- Dann generiert ein Sprachmodell aus diesen Passagen eine zusammenhängende Antwort.
Stufe eins ist Retrieval. Stufe zwei ist Generierung. Und wer sich Stufe eins genauer anschaut, erkennt etwas Vertrautes.
Googles eigene Vertex-AI-Dokumentation beschreibt den Retrieval-Schritt wörtlich als das, was er technisch ist: die Aufgabe der Informationssuche. Die Aufgabe lautet, aus einer großen Menge an Texten diejenigen zu finden, die für eine bestimmte Anfrage am relevantesten sind. Genau das tut eine Suchmaschine seit Jahrzehnten.
Was ist Vertex AI?
In diesem Artikel beziehe ich mich mehrfach auf Googles Vertex-AI-Dokumentation. Vertex AI ist Googles Cloud-Plattform, über die Entwickler eigene KI-gestützte Suchanwendungen und RAG-Systeme bauen können. Die offizielle Dokumentation richtet sich an Entwickler, nicht an SEOs. Aber sie gibt uns einen seltenen Einblick in die technischen Prinzipien, nach denen Google Retrieval, Ranking und Grounding umsetzt. Die Dokumentation beschreibt kein internes Google-System, sondern ein Entwickler-Tool. Aber die Architekturprinzipien, die sie offenlegt, sind konsistent mit dem, was aus den DOJ-Kartellunterlagen, dem API-Leak und unabhängigen Analysen bekannt ist.
Und nicht nur das Prinzip ist dasselbe. Auch die konkreten Verfahren überlappen sich. Googles Retrieval-Pipeline im AI Mode arbeitet laut Mike Kings Analyse als sogenanntes Hybrid Retrieval: Für jede Teilfrage laufen zwei Suchläufe parallel. Der erste ist eine klassische lexikalische Suche über Googles invertierten Index.
Was ist ein invertierter Index?
Ein invertierter Index ist die grundlegende Datenstruktur, mit der Suchmaschinen arbeiten. Er funktioniert wie ein Stichwortverzeichnis in einem Fachbuch, nur umgekehrt: Statt zu einem Kapitel die Stichworte aufzulisten, listet er zu jedem Stichwort alle Dokumente auf, in denen es vorkommt. Wenn du „Wärmepumpe“ googelst, schlägt Google nicht jede Website einzeln durch. Stattdessen schaut es in seinem invertierten Index nach, welche Dokumente das Wort „Wärmepumpe“ enthalten, und ruft diese Liste in Millisekunden ab. Dieses Prinzip existiert, seit es Suchmaschinen gibt.
Ein Algorithmus namens BM25 gewichtet die Treffer nach Häufigkeit und Seltenheit der Suchbegriffe im Verhältnis zum gesamten Dokumentenbestand. Das ist keine KI. Das ist Statistik, die älter ist als Google selbst. Diese lexikalische Suche ist besonders stark bei exakten Treffern: Produktnummern, Eigennamen, seltene Fachbegriffe.
Der zweite Suchlauf ist eine semantische Suche über Googles Embedding-Index. Dabei wird die Suchanfrage in einen mathematischen Vektor umgewandelt, der nicht die Wörter, sondern die Bedeutung der Anfrage repräsentiert. Dieser Vektor wird mit den Vektoren der gespeicherten Textabschnitte verglichen. Was im Vektorraum nah beieinanderliegt, gilt als semantisch relevant, auch wenn kein einziges Wort der Suchanfrage im Text vorkommt. iPullRank beschreibt, dass Google hier vermutlich mit sogenannten Multivektor-Repräsentationen arbeitet: Ein Dokument wird in mehrere semantische Segmente zerlegt, jedes mit einem eigenen Embedding-Vektor. Das erhöht die Treffergenauigkeit auf Abschnittsebene.
Beide Ergebnismengen werden zusammengeführt, normalisiert und durch ein Reranking-Modell geschickt, einen sogenannten Cross-Encoder, der die endgültige Relevanzreihenfolge bestimmt. Soweit der Retrieval-Schritt von RAG.
Jetzt die entscheidende Frage: Was davon ist neu?
Die lexikalische Suche über den invertierten Index existiert, seit es Suchmaschinen gibt. Die semantische Suche über Embedding-Vektoren hat in der Google-Suche spätestens seit der BERT-Integration (2019) an Bedeutung gewonnen, mit Vorläufern wie RankBrain (2015), das erstmals maschinelles Lernen in die Query-Interpretation brachte. Die Kombination beider Verfahren zu einem hybriden System beschreibt iPullRank selbst als Standardarchitektur moderner Suchsysteme. Und das Reranking durch einen Cross-Encoder ist kein Spezifikum der KI-Suche, sondern ein etablierter Baustein jeder ernsthaften Sucharchitektur.
Was bleibt, ist die zweite Stufe: die Generation. Hier wird es komplexer, als der Begriff „Generation“ vermuten lässt. Es ist nicht ein einzelnes Sprachmodell, das eine Antwort schreibt. iPullRank beschreibt in der Architecture-Analyse, dass der finale Kandidatenpool, oft Dutzende Passagen aus verschiedenen Quellen, als sogenannter Grounding Context an Googles Gemini-Modelle übergeben wird. Dabei kommen je nach Informationsbedarf unterschiedliche, spezialisierte Modelle zum Einsatz: eines für Vergleiche, eines für Zusammenfassungen, eines für strukturierte Daten. King beschreibt das in seiner AI-Mode-Analyse als „ensemble cast with a rotating spotlight.“ Bei AI Overviews ist die Synthese auf ein festes Token-Budget beschränkt. Bei AI Mode ist sie konversationell und kann über mehrere Runden hinweg Kontext aufbauen. In beiden Fällen gilt: Die Ausgabe ist kein Freitext. Sie ist gebunden an das, was das Retrieval geliefert hat.
Und selbst diese Generation wird nicht unkontrolliert freigelassen. Googles Vertex-AI-Dokumentation beschreibt einen sogenannten Support Score: ein Wert zwischen 0 und 1, der misst, wie gut jede einzelne Behauptung in der generierten Antwort durch die zuvor gefundenen Quellentexte gestützt wird. Behauptungen, die nur teilweise durch die Quellen gedeckt sind, gelten als „ungrounded“ und erhalten keine Quellenverweise. Das Sprachmodell generiert also nicht frei. Es generiert innerhalb der Grenzen dessen, was das Retrieval geliefert hat. Die Qualität der Antwort ist direkt abhängig von der Qualität der Suche.
Das bedeutet: Wer in der Retrieval-Schicht nicht gefunden wird, existiert für die Generation nicht. Und wer in der Retrieval-Schicht gefunden werden will, muss genau das tun, was professionelle Suchmaschinenoptimierung seit Jahren verlangt: Inhalte so aufbauen, dass sie sowohl lexikalisch als auch semantisch auffindbar sind, thematisch vollständig, auf Absatzebene eigenständig verständlich, und durch kontextuelle Autorität gestützt.
iPullRank hat mit ihrem AI Search Manual das bisher umfassendste Werk zu GEO veröffentlicht und rahmt das Ganze als grundlegenden Umbruch. Ich halte das Manual für fachlich stark. Aber wenn die eigene Architecture-Analyse zeigt, dass alle generativen Suchsysteme auf denselben Grundbausteinen basieren, und dass die Tore, die ein Inhalt passieren muss, „consistent in concept“ sind, dann ist die Frage nicht, ob wir eine neue Disziplin brauchen. Dann ist die Frage, ob wir die bestehende verstanden haben.
Der eine Unterschied, der bleibt: Der Faktor Mensch
Im vorherigen Abschnitt habe ich gezeigt, dass die Retrieval-Schicht von KI-Suche und klassischer Suche auf denselben Mechanismen basiert. Invertierter Index, Embedding-Vektoren, Hybrid Retrieval, Cross-Encoder-Reranking. Die Frage ist: Wenn das alles so ähnlich ist, warum liefern beide Systeme trotzdem unterschiedliche Ergebnisse?
Die Antwort ist der Mensch.
Googles Ranking basiert nicht nur auf Retrieval und Reranking. Es basiert auf einem Re-Ranking-System namens NavBoost, das Nutzerverhalten auswertet, um die Suchergebnisse nachzujustieren. Pandu Nayak, einer der ranghöchsten Google-Ingenieure, hat im DOJ-Kartellverfahren unter Eid ausgesagt, wie das System funktioniert: NavBoost nutzt 13 Monate aggregierter Klickdaten, um die Kandidatenmenge nach dem initialen Retrieval von Zehntausenden auf einige Hundert zu filtern. Es ist kein finaler Twiddler, der am Ende kleine Anpassungen vornimmt. Es ist ein massiver Filter, der die Rangfolge fundamental verändert.
NavBoost trackt dabei drei zentrale Metriken. goodClicks: Der Nutzer klickt auf ein Ergebnis und bleibt. badClicks: Der Nutzer klickt und springt sofort zurück zur Ergebnisseite, das sogenannte Pogo-Sticking. Und lastLongestClicks: Der letzte Klick einer Suchsitzung, auf dem der Nutzer am längsten verweilt. Cyrus Shepard hat diese Signale in seiner Analyse systematisch aufgearbeitet, gestützt auf API-Leak, DOJ-Unterlagen und Google-Patente. Sein Fazit: Google versucht mit diesen Signalen drei Fragen zu beantworten.
- Ist dieses Ergebnis relevant?
- Ist der Inhalt nützlich?
- Und befriedigt er die Suchanfrage vollständig?
Dabei ist NavBoost alles andere als primitiv. Das System wertet nicht einfach aus, wie lange jemand auf einer Seite bleibt. Shaun Anderson beschreibt in seinem E-Book Strategic SEO 2025, wie NavBoost die Klickdaten durch sogenanntes Slicing nach Geografie, Gerätetyp und Suchanfragekontext segmentiert. Für eine mobile Suche aus Lübeck gewichtet NavBoost andere Ergebnisse als für eine Desktop-Suche aus München, selbst bei identischer Suchanfrage. Dazu kommt ein Verfahren, das manipulierte oder verrauschte Signale herausfiltert. Die Daten werden also nicht roh verwendet, sondern mehrfach kontextualisiert und bereinigt.
Google selbst nennt Klicks eines seiner drei fundamentalen Signale. Im DOJ-Verfahren hat Ingenieur HJ Kim erklärt, dass Googles Basis-Relevanzscore aus drei Komponenten besteht: Anchors (Links), Body (Textinhalt) und Clicks (Nutzerinteraktion). Diese ABC-Signale bilden das Fundament, auf dem alle weiteren Ranking-Schichten aufbauen.
Und jetzt der Punkt: Ein KI-Chatbot hat keinen Browser. Er klickt auf keine Ergebnisse. Er springt nicht zurück. Er verweilt nirgends. Er hat kein Suchverhalten, das NavBoost auswerten könnte. Die gesamte Feedback-Schleife, die in der klassischen Suche dafür sorgt, dass gute Ergebnisse nach oben steigen und schlechte nach unten fallen, existiert in der KI-Suche nicht.
Das war bisher mein Kernargument: Wenn man diese menschliche Feedback-Schleife aus SEO herausrechnet, bleibt das übrig, was die Branche GEO nennt. Retrieval, Relevanz, thematische Autorität. Alles, was eine Maschine ohne menschliches Zutun bewerten kann.
Eine saubere Unterscheidung. Vielleicht zu sauber.
Warum auch dieser Unterschied nicht hält
Die Trennung klingt klar: NavBoost auf der einen Seite, kein Nutzerverhalten auf der anderen. Nur: Drei Befunde zeigen, dass diese Trennung in der Praxis durchlässiger ist, als ich sie dargestellt habe.
Befund 1: Klickdaten stecken im Ranking-Modell
Die Ranking-Modelle, mit denen Google seine Suchergebnisse bewertet, werden nicht nur auf algorithmische Signale trainiert. RankEmbedBERT, eines der zentralen Ranking-Modelle, basiert laut Andersons Analyse der DOJ-Unterlagen auf zwei Datenquellen: 70 Tage Suchprotokolle, die Klickdaten enthalten, und Bewertungen menschlicher Quality Rater. Googles VP of Search hat im DOJ-Verfahren bestätigt, dass diese Rater-Bewertungen keine nachgelagerten Benchmarks sind, sondern direkte Trainingsdaten für das Modell. RankEmbedBERT wird also sowohl von menschlichem Klickverhalten als auch von menschlichen Qualitätsurteilen geformt.
Und jetzt der entscheidende Punkt: Wenn Google AI Overviews oder AI Mode Suchergebnisse als Grounding Context für die Antwortgenerierung verwendet, dann verwendet es Ergebnisse, die durch ein Ranking-Modell geformt wurden, in dem Klickdaten und menschliche Urteile bereits eingebacken sind. Die menschliche Feedback-Schleife ist nicht abwesend. Sie ist eine Schicht tiefer gewandert, in die Gewichte des Modells.
Cyrus Shepard hat diesen Mechanismus in seiner Analyse auf den Punkt gebracht: AI Overviews und AI Mode fassen typischerweise Top-Ergebnisse zusammen. Und diese Top-Ergebnisse sind ihrerseits durch NavBoost und RankEmbedBERT geformt, also durch Klicksignale. Der Mensch ist nicht aus dem System verschwunden. Er ist nur nicht mehr sichtbar.
Befund 2: Sogar ChatGPT ist abhängig von Googles Ranking
Shepard zeigt einen weiteren Weg, auf dem Klicksignale in KI-Antworten landen: ChatGPT greift für seine Websuche offenbar auf Google-Suchergebnisse zurück, nicht nur auf Bings eigenen Index. Shepard stützt sich dabei auf Berichte von SearchEngineLand und Tom’s Guide, die Übereinstimmungen zwischen ChatGPT-Ergebnissen und Google-SERPs dokumentiert haben. Microsofts Bing-Ergebnisse scheinen allein nicht auszureichen, um Googles Treffergenauigkeit bei seltenen oder komplexen Anfragen zu replizieren. Wenn das stimmt, dann sind auch ChatGPTs Antworten indirekt durch Googles Klicksignale beeinflusst, obwohl OpenAI kein eigenes Nutzerverhalten auf Webseiten auswertet.
Befund 3: Und trotzdem stimmt die Gegenrichtung auch
Hier wird es unbequem für meine Argumentation, und ich will ehrlich damit umgehen. Denn die Daten zeigen auch das Gegenteil. iPullRank berichtet in ihrem AI Search Manual, dass rund 60 % der AI-Overview-Zitate von URLs stammen, die nicht einmal in den Top 20 der organischen Suchergebnisse ranken. 60 Prozent. Das ist keine Randerscheinung. Das bedeutet: Googles KI-Retrieval kann Inhalte finden und zitieren, die im klassischen Ranking, also in dem System, das NavBoost formt, gar nicht auf Seite 1 oder 2 stehen.
Wie passt das zusammen?
Die Erklärung liegt in einem Detail, das leicht übersehen wird: NavBoost ist ein Re-Ranking-System, kein Retrieval-System. Nayak selbst hat das im DOJ-Verfahren klargestellt: NavBoost greift erst, nachdem Dokumente bereits als relevant identifiziert wurden. Es justiert die Reihenfolge innerhalb einer Kandidatenmenge. Und diese Kandidatenmenge wird für eine bestimmte Suchanfrage zusammengestellt, mit Klickdaten, die über 13 Monate für genau diese Suchanfrage gesammelt wurden.
Googles AI Mode arbeitet aber nicht mit einer einzigen Suchanfrage. Es arbeitet mit dem, was Google in seiner eigenen Dokumentation als Query Fan-out bezeichnet: Der Prompt wird in mehrere Teilfragen zerlegt, die parallel gegen verschiedene Datenquellen laufen. Und für diese automatisch generierten Teilfragen existieren oft keine NavBoost-Daten, weil sie in dieser Form noch nie von einem Menschen gesucht wurden. Eine Seite, die für die ursprüngliche Suchanfrage auf Position 47 steht, kann für eine der Teilfragen hochrelevant sein, weil der Textabschnitt semantisch exakt passt. NavBoost hat zu dieser Teilfrage schlicht keine Klickdaten, die dagegensprechen könnten.
Meine bisherige Trennung, SEO gleich mit Mensch, GEO gleich ohne Mensch, war deshalb nicht falsch, aber zu binär. Die Realität ist: Der Faktor Mensch ist in GEO nicht abwesend, er ist indirekt eingebettet. Und gleichzeitig hat GEO einen Retrieval-Pfad, der ohne menschliche Feedback-Schleife funktioniert. Beides ist wahr.
Die Konvergenz: Google baut kein zweites System
Beide Befunde deuten in dieselbe Richtung. Und Google selbst bestätigt das. Nicht durch Pressestatements, sondern durch die Architektur seiner Systeme.
Googles eigene Dokumentation zu AI Overviews und AI Mode formuliert es explizit: Die Kern-Ranking-Systeme der klassischen Websuche sind in AI Overviews integriert. Wörtlich schreibt Google, dass AI Overviews darauf ausgelegt sind, Informationen zu liefern, die durch die besten Webergebnisse gestützt werden. AI Mode sei in denselben Ranking- und Sicherheitssystemen verankert, die Google seit über 20 Jahren für die Websuche verfeinert. Auf der Retrieval-Ebene teilen sich klassische Suche und AI Mode also dieselbe Infrastruktur. Aber darauf sitzt ein eigener Processing-Layer, den die klassische Suche nicht hat. Mike King beschreibt in seiner AI-Mode-Analyse, wie Google ein Patent für „Pairwise Ranking Prompting“ angemeldet hat: Ein Sprachmodell vergleicht dabei zwei Textpassagen direkt miteinander und entscheidet, welche für die Anfrage relevanter ist. Das ist kein deterministisches Scoring wie in der klassischen Suche. Das ist eine modellvermittelte, probabilistische Relevanzbewertung, bei der dein Absatz Kopf an Kopf gegen den Absatz eines Konkurrenten antritt.
Und auf der Feature-Ebene läuft die Überführung: Funktionen und Features aus AI Mode sollen sukzessive in die Kern-Sucherfahrung integriert werden. Googles CEO hat AI Mode laut iPullRank als die Zukunft der Suche bezeichnet, die langfristig zur Standardfunktion werden soll. Das ist keine Koexistenz zweier Systeme. Das ist eine Überführung.
Ein konkreter Mechanismus zeigt, wie eng die beiden Welten bereits verzahnt sind. Googles Vertex-AI-Dokumentation beschreibt ein Verfahren namens Dynamic Retrieval. Dabei entscheidet das System pro Anfrage, ob es die Antwort auf Basis des Suchindex erstellen soll oder ob das Trainingswissen des Sprachmodells ausreicht. Jeder Anfrage wird ein Prediction Score zwischen 0 und 1 zugewiesen. Wer nach dem Ergebnis des letzten Formel-1-Rennens fragt, bekommt einen hohen Score, also Grounding über den Suchindex. Wer nach der Hauptstadt von Frankreich fragt, bekommt einen niedrigen Score, das Modell antwortet aus dem Trainingswissen. Der Schwellenwert liegt standardmäßig bei 0,7.
Was bedeutet das? Dass das System nicht zwischen „klassischer Suche“ und „KI-Suche“ umschaltet wie zwischen zwei Modi. Es entscheidet pro Teilfrage, wie viel Suchindex es braucht. Ein einziger Prompt kann gleichzeitig Teilfragen enthalten, die über den Suchindex beantwortet werden, und Teilfragen, die aus dem Trainingswissen kommen. Die Grenze zwischen SEO-relevantem Retrieval und LLM-Wissen verläuft nicht zwischen zwei Systemen. Sie verläuft innerhalb jeder einzelnen Antwort.
Wer in dieser Landschaft zwischen „SEO“ und „GEO“ unterscheiden will, muss erklären, wo genau die Grenze liegt. Bei einem Prediction Score von 0,7? Bei 0,5? Bei einer Teilfrage, für die NavBoost-Daten existieren, vs. einer, für die keine existieren? Die Antwort ist: Es gibt keine klare Grenze. Und Google baut offensichtlich auch keine.
Dazu kommt ein Faktor, der die Konvergenz-These an einer Stelle ehrlich einschränkt: Personalisierung durch User Embeddings. King beschreibt ein Google-Patent, das einen persistenten Vektor pro Nutzer erstellt, abgeleitet aus langfristigem Suchverhalten, Klickmustern, Geräteinteraktionen und Daten aus dem Google-Ökosystem.
Dieser Vektor beeinflusst in AI Mode jede Stufe: welche Teilfragen im Fan-out priorisiert werden, welche Passagen im Retrieval bevorzugt werden, und wie die Antwort formuliert wird. Zwei Nutzer mit derselben Suchanfrage können unterschiedliche Antworten erhalten. Nicht weil die Anfrage mehrdeutig ist, sondern weil die Systeme unterschiedliche Nutzerprofile haben. Die klassische Suche personalisiert seit Jahren über Standort und Gerätetyp. Aber ein nutzerspezifischer Embedding-Vektor, der die gesamte Antwortgenerierung durchdringt, ist qualitativ etwas anderes. Hier liegt ein genuiner Unterschied zwischen klassischer Suche und AI Mode, den man nicht wegargumentieren sollte.
AI Overviews erscheinen laut iPullRank mittlerweile bei über 50 Prozent aller Google-Suchen (Stand 2025). Das ist kein Experimentierfeld mehr. Das ist die Suche.
Warum die Debatte das eigentliche Problem verdeckt
Trotzdem wird in der Branche eine Debatte geführt, als ginge es um zwei verschiedene Welten. iPullRank empfiehlt, SEO-Teams zu GEO-Teams umzubauen und „entirely new categories of expertise“ zu entwickeln. 85,5 Prozent der befragten SEO-Experten glauben laut iPullRank, dass generative KI traditionelle SEO-Rollen ersetzen wird.
Schaut man sich an, was diese „neuen Expertisen“ konkret umfassen, wird es interessant. Semantisches Verständnis von Suchanfragen. Thematische Autorität. Content, der auf Absatzebene eigenständig verständlich ist. Strukturierte Daten. Entitäts-basierte Optimierung. Das sind keine neuen Kompetenzen. Das ist das, was ein kompetenter SEO seit der BERT-Integration 2018 beherrschen sollte.
Ich habe das an anderer Stelle ausführlich beschrieben: Die SEO-Branche hat kein Zugangsproblem. Jeder darf sich SEO nennen. Es gibt keine geschützte Ausbildung, keinen relevanten Studiengang, keine Zertifizierung mit Aussagekraft. Und genau das führt dazu, dass ein erheblicher Teil der Agenturen und Freelancer mit Methoden arbeitet, die seit Jahren veraltet sind. Keyword-Listen auf Basis von Suchvolumen. Texte, die auf Keyword-Dichte optimiert werden. Backlinks in Massen. Das war 2012 eine akzeptable Arbeitsweise. Heute nicht mehr.
GEO ändert an diesem Problem nichts. Im Gegenteil. Das GEO-Label gibt Agenturen, die semantische Optimierung nie verstanden haben, eine neue Verpackung für dasselbe Defizit. Wer gestern nicht wusste, wie Google natürliche Sprache versteht, weiß es heute nicht besser, nur weil er sein Angebot von „SEO“ in „GEO“ umbenennt. Wer die Grundlagen beherrscht, nämlich wie Inhalte gefunden, bewertet und für relevant befunden werden, der ist für beide Ausgabeformate gerüstet. Und wer sie nicht beherrscht, dem hilft kein Rebranding.
Es gibt allerdings einen Punkt, an dem die GEO-Diskussion einen echten Beitrag leistet, und den will ich nicht unterschlagen. Die Frage, wie Inhalte auf Absatzebene so formuliert werden, dass sie als eigenständige Antwortbausteine funktionieren, ist in der klassischen SEO-Praxis unterbelichtet. Nicht weil das Prinzip neu wäre. Passage Ranking gibt es bei Google seit 2021. Aber die operative Konsequenz, nämlich dass jeder Absatz für sich stehen muss, wird in vielen SEO-Workflows nicht umgesetzt. Wenn die GEO-Debatte dazu führt, dass mehr SEOs anfangen, auf Absatzebene zu denken statt auf Seitenebene, dann hat sie zumindest einen praktischen Nutzen gehabt.
Was bleibt
Die Frage „GEO oder SEO?“ ist falsch gestellt. GEO ist eine Teilmenge von SEO, keine eigene Disziplin. Aber die Trennung „SEO = mit Mensch, GEO = ohne Mensch“, die ich selbst vertreten habe, war zu sauber. Die Systeme sind stärker verwoben, als ich es dargestellt habe.
Was sich daraus für die Praxis ergibt, lässt sich in drei Fragen fassen.
Erstens: Verstehst du, wie deine Inhalte gefunden werden?
Nicht „gefunden“ im Sinne von „rankt auf Seite 1″. Sondern: Verstehst du, dass Google zwei parallele Suchläufe fährt, einen lexikalischen und einen semantischen? Dass deine Inhalte sowohl über exakte Begriffe als auch über semantische Nähe gefunden werden müssen? Dass Googles AI Mode deine Inhalte in Teilfragen zerlegt, die du nie als Suchanfrage in einem Tool sehen wirst? Wenn dein SEO-Dienstleister auf diese Fragen mit Keyword-Listen und Suchvolumen antwortet, hast du ein Problem. Und das Problem heißt nicht „fehlende GEO-Kompetenz“. Es heißt fehlende SEO-Kompetenz.
Zweitens: Funktionieren deine Absätze eigenständig?
Die KI-Suche bewertet nicht Seiten. Sie bewertet Textabschnitte. Jeder Absatz ist ein eigenständiger Antwortkandidat, der mit den Absätzen tausender anderer Seiten konkurriert. Ein Absatz, der nur im Kontext des restlichen Textes Sinn ergibt, fällt in diesem Wettbewerb durch. Prüfe deine wichtigsten Seiten: Nimm einen beliebigen Absatz aus der Mitte des Textes und lies ihn isoliert. Beantwortet er eine konkrete Frage? Ist er ohne den Rest der Seite verständlich? Wenn nicht, ist er für KI-Retrieval unbrauchbar. Googles Vertex-AI-Dokumentation bewertet über einen sogenannten Support Score (0 bis 1), wie gut jede einzelne Behauptung in einer KI-Antwort durch die zugrunde liegenden Quellentexte gestützt wird. Absätze, die eine Frage eigenständig und vollständig beantworten, erzielen dort höhere Werte.
Drittens: Bist du die letzte Quelle, die jemand braucht?
NavBoost misst, ob ein Nutzer nach dem Besuch deiner Seite aufhört zu suchen. Der lastLongestClick ist das stärkste Zufriedenheitssignal, das Google kennt. Und auch wenn KI-Chatbots keine Klickdaten erzeugen, gilt das Prinzip dahinter: Inhalte, die eine Frage vollständig beantworten, werden zitiert. Inhalte, die nur anreißen, werden übersprungen. Frag dich bei jedem Absatz: Muss der Leser danach noch woanders suchen? Wenn ja, hast du die Frage nicht beantwortet. Und dann wird auch kein KI-System dich als Quelle nutzen.
Über diesen Artikel
Die inhaltliche Verantwortung für jeden Artikel auf diesem Blog liegt bei mir, Patrick Stolp. Thema, These, Recherche und fachliche Prüfung sind meine Arbeit – hier wird nichts veröffentlicht, das ich nicht selbst konzipiert, geschrieben und als korrekt verifiziert habe. Generative KI (Claude von Anthropic) kommt punktuell als Werkzeug zum Einsatz – etwa für Formulierungsentwürfe oder das Gegenlesen technischer Erklärungen. Kein KI-Output landet ungeprüft oder unverändert auf dieser Seite. Beitragsbilder werden mit Google Nano Banana 2 erstellt.
Mehr dazu in meinen Redaktionsrichtlinien.