Daten (mit KI) in der Google Search Console analysieren – und wie sich Googles Ranking-System in Graphen manifestiert

Die Google Search Console ist das einzige Analysetool, das direkt von Google kommt und echte Ranking-Daten liefert. Kein Drittanbieter-Tool hat Zugang zu diesen Daten — Ahrefs, Semrush und Sistrix schätzen Sichtbarkeit auf Basis eigener Crawler und Keyword-Datenbanken. Die GSC zeigt, für welche Suchanfragen Google deine Seiten tatsächlich ausgespielt hat, wie oft, auf welcher Position und mit welcher Klickrate.
Trotzdem nutzen die meisten SEOs die Search Console als Reporting-Dashboard. Sie schauen auf Klicks, vergleichen Zeiträume, exportieren Tabellen. Das ist nicht falsch. Aber es ist ungefähr so, als würde ein Arzt den Blutdruck messen und dann aufhören, statt das Ergebnis im Kontext des Kreislaufsystems zu interpretieren.
Die GSC-Daten enthalten diagnostische Signale, die weit über „Traffic rauf oder runter“ hinausgehen. Aber um sie zu lesen, brauchst du ein Verständnis davon, wie Googles Ranking-System funktioniert — welche Mechanismen welche Spuren in den Daten hinterlassen. Ohne dieses Verständnis stellst du die falschen Fragen.
Und seit Kurzem gibt es drei Entwicklungen, die das Fragenstellen technisch radikal vereinfachen: Googles eigene KI-Konfiguration in der GSC, Open-Source-MCP-Server, die Claude direkt an die GSC-API anbinden, und Embedding-basierte Analysen wie die in meinem letzten Artikel vorgestellte Methode. Alle drei senken die Zugangshürde zur Datenabfrage auf nahe null.
Aber keines dieser Werkzeuge ersetzt die Frage, die du stellst. Und die richtige Frage setzt voraus, dass du weißt, welche Mechanismen hinter den Daten arbeiten.
Was hinter dem GSC-Dashboard passiert oder: Googles Ranking-Pipeline
Bevor wir in die Daten schauen, muss klar sein, was die Daten überhaupt abbilden. Die Search Console zeigt dir das Ergebnis von Googles Ranking-Prozess — Positionen, Klicks, Impressionen. Sie zeigt dir nicht den Prozess selbst. Aber wenn du den Prozess verstehst, kannst du aus dem Ergebnis Rückschlüsse ziehen, die über bloße Bestandsaufnahme hinausgehen.
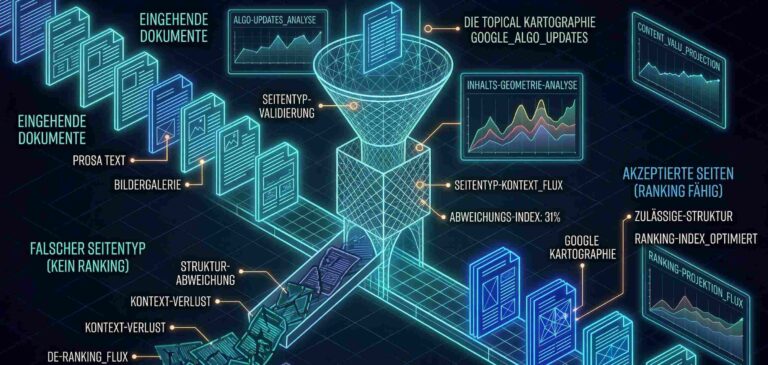
Googles Ranking-System ist keine lineare Formel (Jaja, ihr Mathematiker, ich höre eure Gedanken. Es steckt durchaus Lineare Algebra drin. Spielt hier aber keine Rolle). Die DOJ-Unterlagen, der Content-Warehouse-API-Leak von 2024 und die Analysen von Shaun Anderson haben ein Bild gezeichnet, das die Branche lange nicht hatte: eine mehrstufige Pipeline, in der verschiedene Systeme nacheinander arbeiten — jedes mit einer eigenen Funktion.
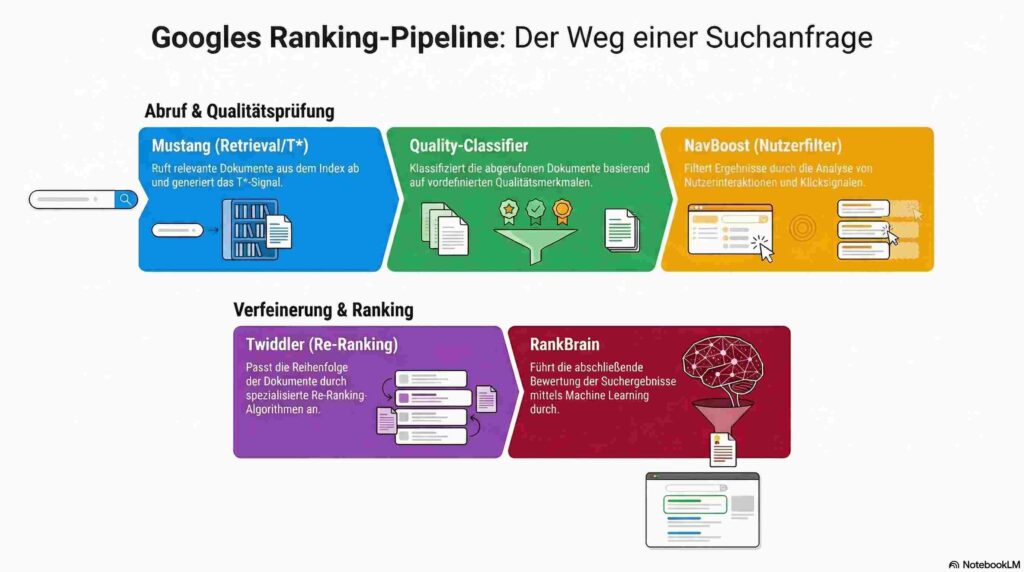
Retrieval: Mustang und der erste Schnitt
Am Anfang steht die Frage: Welche Dokumente kommen überhaupt als Kandidaten in Betracht? Das übernimmt ein System namens Mustang. Es ist Googles Primary Scoring System — der erste Durchlauf durch den Index, der aus Milliarden von Dokumenten eine handhabbare Kandidatenmenge erzeugt. Mustang bewertet Dokumente auf Basis von Relevanz-Signalen: Stimmen die Terme überein? Wie stark ist die thematische Übereinstimmung?
Aus dem DOJ-Verfahren wissen wir, dass Google diese grundlegende Relevanzbewertung intern als T* (Topicality) bezeichnet — zusammengesetzt aus den sogenannten „ABC-Signalen“: Anchors (Ankertexte eingehender Links), Body (der Seiteninhalt selbst) und Clicks (Nutzerverhalten). Pandu Nayak, Googles VP of Search, hat unter Eid bestätigt, dass Ankertexte „einen sehr wertvollen Hinweis darauf geben, wofür die Zielseite relevant ist“.
Was Mustang produziert, ist eine provisorische Rangfolge. Kein finales Ranking — ein Ausgangspunkt.
Quality Classification: drin oder draußen
Parallel — oder unmittelbar danach — laufen Classifier. Das sind Systeme, die Dokumente nicht gegeneinander ranken, sondern einzeln bewerten und in Klassen einteilen.
Olaf Kopp hat die Unterscheidung zwischen Scoring und Classification für Suchmaschinen systematisch aufgearbeitet — eine Differenzierung, die in der SEO-Branche erstaunlich selten sauber getroffen wird. Der Kern: Ein Scorer vergibt Punkte relativ zu einer Suchanfrage und braucht immer mindestens ein Vergleichsdokument. Sein Output ist ein kontinuierlicher Wert — zum Beispiel ein BM25-Score von 8,9. Ein Classifier vergibt Kategorien — unabhängig von der Suchanfrage, unabhängig von anderen Dokumenten. Sein Output ist: Klasse A oder Klasse B. Qualifiziert oder nicht qualifiziert. Und er nutzt Schwellenwerte, um die Klassen voneinander zu trennen.
Scorer vs. Classifier
In der SEO-Branche werden Ranking-Signale oft behandelt, als wären sie alle dasselbe. In Wirklichkeit arbeiten zwei grundlegend verschiedene Mechanismen zusammen. Scorer ranken Dokumente gegeneinander — sie erzeugen eine Reihenfolge. Classifier stufen Dokumente in Qualitätsklassen ein — sie entscheiden, ob ein Dokument überhaupt in den Ranking-Pool kommt. Google selbst bestätigt, dass Helpful Content ein Classifier ist. Kopp ordnet E-E-A-T als das übergeordnete Quality-Classifier-Konzept ein, das die Bewertungen verschiedener einzelner Classifier zusammenfasst.
Aus dem API-Leak kennen wir eine konkrete Struktur, die auf diesen Mechanismus hindeutet: Der SegIndexer ordnet Dokumente bereits bei der Indizierung in qualitätsbasierte Tiers ein — mit internen Bezeichnungen wie „Base“, „Zeppelins“ und „Landfills“. Das ist keine Relevanzbewertung. Das ist Vorklassifikation: Bevor überhaupt eine Suchanfrage gestellt wird, hat Google bereits entschieden, in welchem Qualitäts-Tier ein Dokument liegt.
Daraus folgt für die Praxis: Ein Dokument, das vom Classifier in eine niedrigere Klasse eingestuft wird, kommt für bestimmte Suchanfragen gar nicht erst in den Kandidatenpool — unabhängig davon, wie relevant sein Inhalt wäre. Anderson beschreibt es so: Für hochkompetitive Queries erzeugt Mustang möglicherweise eine Kandidatenmenge, die nur aus Dokumenten besteht, die einen bestimmten Qualitätsschwellenwert überschreiten. Ein neuer, autoritätsschwacher Blog wird herausgefiltert, bevor sein Content jemals tiefgehend bewertet wird. Das Dokument wird nicht schlecht gerankt. Es wird gar nicht gerankt.
Die Dokumente, die nach Retrieval und Classification übrig sind, durchlaufen mehrere Re-Ranking-Stufen. Aus dem API-Leak und den DOJ-Dokumenten kennen wir zwei zentrale Systeme.
Twiddler sind spezialisierte Re-Ranking-Funktionen, die den initialen Relevanz-Score eines Dokuments nachjustieren. Shaun Anderson identifiziert aus dem Leak unter anderem einen FreshnessTwiddler (Boost für aktuelle Inhalte) und QualityBoost (Nachjustierung auf Basis von Qualitätssignalen). Twiddler verändern nicht die Klassifikation eines Dokuments. Sie verändern seine Position innerhalb des Ranking-Pools, in den es bereits aufgenommen wurde.
NavBoost ist das nutzerbasierte Re-Ranking-System. Pandu Nayak hat im DOJ-Verfahren unter Eid ausgesagt, wie es funktioniert: NavBoost nutzt 13 Monate aggregierter Klickdaten, um die Kandidatenmenge nach dem initialen Retrieval von Zehntausenden auf einige Hundert zu filtern. Es trackt dabei goodClicks (Nutzer scheint zufrieden), badClicks (Nutzer springt sofort zurück) und lastLongestClicks (der letzte Klick, auf dem der Nutzer am längsten verweilt — ein besonders starkes Zufriedenheitssignal). Nayak stellte klar: NavBoost ist kein finaler Twiddler, der am Ende kleine Anpassungen vornimmt. Es ist ein mächtiger Filter, der früh in der Pipeline angewendet wird.
Erst die deutlich kleinere, von NavBoost gefilterte Ergebnismenge wird an die rechenintensivsten ML-Modelle wie RankBrain weitergereicht — dann für die finale Reihenfolge.
Die Pipeline als Ganzes
Zusammengenommen ergibt sich ein System mit mindestens vier Ebenen:
Mustang erzeugt eine provisorische Rangfolge auf Basis von Relevanz-Signalen (T*: Anchors, Body, Clicks).
Quality-Classifier stufen Dokumente in Qualitätsklassen ein — unabhängig von der Suchanfrage, auf Basis von Merkmalen wie contentEffort, OriginalContentScore, siteAuthority.
NavBoost filtert auf Basis historischer Nutzerinteraktionen — 13 Monate Klickdaten, goodClicks, badClicks, lastLongestClicks.
Twiddler justieren die Positionen innerhalb des verbleibenden Pools nach — Freshness, Quality, Diversität.
RankBrain und weitere ML-Modelle entscheiden über die finale Reihenfolge.
Jede dieser Ebenen hinterlässt Spuren in den GSC-Daten. Aber die GSC zeigt dir nur das Endergebnis — die Position, die nach allen Stufen übrig bleibt. Um die Daten analytisch zu lesen, musst du rückwärts denken: Welche Veränderung in meinen Daten könnte auf welche Stufe der Pipeline zurückgehen?
Was die GSC nicht zeigt
Bevor wir das tun, eine nüchterne Bestandsaufnahme der Datenlage. Die GSC ist die beste Quelle, die es gibt — aber sie ist nicht vollständig.
Die Daten sind nicht DIE Daten. Google nutzt spezielle Filter und Verfahren, um die Datenmengen handhabbar zu halten. Was du siehst, ist eine repräsentative Auswahl, also nicht die vollständige Realität. Für die meisten Websites ist die Abweichung gering. Für sehr große Websites kann der Unterschied schon substanziell sein.
Anonymisierte Queries fehlen. Suchanfragen, die in einem Zeitraum von zwei bis drei Monaten nur von wenigen Dutzend Nutzern gestellt werden, erscheinen nicht in den GSC-Daten, und zwar aus Datenschutzgründen. Eine Analyse von ZipTie.dev kam 2025 zu dem Ergebnis, dass etwa 50% des Long-Tail-Traffics als anonymisierte Queries unsichtbar bleibt. Die Klicks dieser Queries fließen in die Gesamtzahlen der Diagramme ein, tauchen aber in keiner Tabelle auf.
Die durchschnittliche Position ist ein Aggregat. Sie wird gewichtet über alle Impressionen berechnet, einschließlich personalisierter und lokalisierter Ergebnisse. Bei Keywords mit geringem Suchvolumen kann dieser Wert stark verzerrt sein. Eine „durchschnittliche Position 8″ kann bedeuten, dass du für 90% der Nutzer auf Position 15 stehst und für 10% auf Position 1.
AI Overviews sind nicht separierbar. Impressionen, die durch AI Overviews ausgelöst werden, sind in den regulären Impressionsdaten enthalten. Es gibt keinen nativen Filter, der sie trennt. Wenn deine Impressionen steigen, aber deine Klicks stagnieren, können AI Overviews die Ursache sein, doch die GSC zeigt dir das nicht direkt.
Das Datenfenster beträgt 16 Monate. Ältere Daten sind nicht verfügbar. Für langfristige Trendanalysen, die mehr als ein Jahr abdecken sollen, musst du Daten regelmäßig exportieren oder über die API in ein externes System überführen.
Die API hat ein Limit von 50.000 Zeilen pro Tag, pro Property, pro Suchtyp. Für die meisten Websites reicht das. Für sehr große Projekte ist es eine Einschränkung, die systematische Verzerrungen erzeugen kann, weil die Daten nach Klicks sortiert zurückgegeben werden und der Long Tail abgeschnitten wird.
All das bedeutet nicht, dass die GSC-Daten unbrauchbar sind. Es bedeutet, dass du wissen musst, was du siehst und was du nicht siehst.
Welche Muster in GSC-Daten auf welche Mechanismen hindeuten
Wenn du die Pipeline aus dem vorherigen Abschnitt verstanden hast, kannst du GSC-Daten anders lesen. Nicht als Bestandsaufnahme — „Traffic rauf, Traffic runter“ —, sondern als diagnostisches Signal, das auf bestimmte Stufen der Pipeline zurückschließen lässt.
In der Praxis tauchen dabei Muster auf, die sich über verschiedene Websites, Branchen und Größenordnungen wiederholen. Koray Tugberk Güler hat diese Muster über mehrere Dutzend Projekte hinweg dokumentiert und kategorisiert — von NASDAQ-Unternehmen mit Millionen von Klicks bis zu SaaS-Startups, von E-Commerce-Sites bis zu Gesundheitsportalen in der YMYL-Nische. Was er dabei beobachtet, lässt sich über die Pipeline-Mechanik erklären — auch wenn die konkreten Begriffe, die er für diese Muster verwendet, seine eigenen sind.
Muster 1: Die Treppenformation — positiver Ranking-Zyklus
Das auffälligste Muster in den GSC-Daten einer wachsenden Website ist keine gerade Aufwärtslinie. Es ist eine Treppe: ein Anstieg, dann ein temporärer Rückgang, dann ein Anstieg auf ein höheres Niveau als zuvor. Jedes Tal ist höher als das vorherige. Jeder Peak ist höher als der letzte.
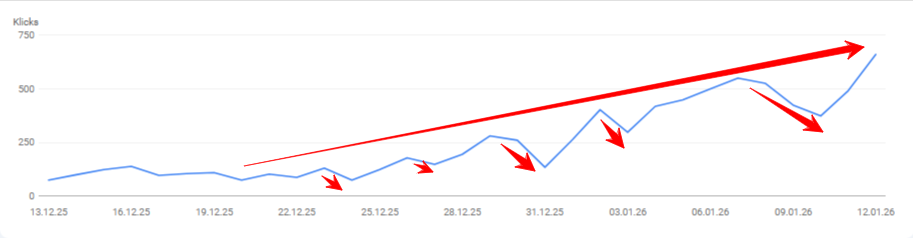
Was du siehst, sind Re-Ranking-Zyklen. Google rankt neue Inhalte zunächst provisorisch ein — das initiale Ranking aus Mustang. Dann beginnt der Testprozess: NavBoost sammelt Nutzerdaten (Klicks, Verweildauer, Rückkehr zur Suche), Twiddler justieren nach. Wenn die Nutzersignale positiv ausfallen, steigt die Position. Wenn Google erneut testet — etwa weil neue Konkurrenz-Dokumente indiziert wurden oder weil ein Freshness-Signal abläuft —, fällt die Position temporär. Und wenn der nächste Test wieder positiv ausfällt, stabilisiert sie sich auf einem höheren Niveau.
Koray nennt den Zustand, der aus diesen Zyklen entsteht, „Positive Ranking State“. Eine Website in einem positiven Ranking-Zyklus zeigt in der GSC ein konsistentes Treppenmuster: Jede Re-Ranking-Runde endet höher als die vorherige. Neue Inhalte, die auf einer solchen Website veröffentlicht werden, starten tendenziell mit besseren initialen Rankings — weil die site-weiten Signale (siteAuthority, historische NavBoost-Daten, Classifier-Einstufung) bereits auf einem Niveau liegen, das dem neuen Dokument einen Vertrauensvorschuss gibt.
Pipeline-Zuordnung: Das Treppenmuster entsteht im Zusammenspiel von NavBoost (testet Nutzerzufriedenheit über 13 Monate Klickdaten) und Twiddlern (justieren Positionen nach). Die provisorische Rangfolge aus Mustang ist der Ausgangspunkt. Die Classifier-Einstufung bestimmt, in welchem Ranking-Pool getestet wird. Die Wellen selbst sind das sichtbare Ergebnis der Re-Ranking-Zyklen.
Muster 2: Der Sprung — Core Updates als Stufenwechsel
Ein zweites Muster betrifft das Verhalten nach Core Updates. Bei Websites, die sich bereits in einem positiven Zyklus befinden, passiert bei einem Core Update oft etwas Unerwartetes: Statt eines graduellen Anstiegs springt die Kurve auf ein neues Niveau. Nicht um 10% höher, sondern auf ein komplett anderes Band. Auch dies kann im oberen GSC-Chart zum Jahreswechsel von ’25 auf ’26 beobachtet werden.
Das ist kein Zufall. Im vorherigen Abschnitt habe ich beschrieben, dass Classifier mit Schwellenwerten arbeiten, die Qualitätsklassen voneinander trennen. Ein Core Update kann diese Schwellenwerte verschieben — oder die Gewichtung der Signale, die in die Klassifikation einfließen, verändern. Wenn eine Website vor dem Update knapp unter einem Schwellenwert lag und das Update die Bewertung so verschiebt, dass sie jetzt darüber liegt, passiert keine graduelle Verbesserung — die Website wird in eine höhere Klasse eingestuft und hat damit Zugang zu einem Ranking-Pool, der ihr vorher verschlossen war. In der GSC sieht das aus wie ein Sprung.
Das Gegenbeispiel existiert natürlich auch: Websites, die knapp über dem Schwellenwert lagen und nach dem Update darunter fallen. Für die sieht es in der GSC aus wie ein plötzlicher Einbruch — nicht weil der Content schlechter geworden ist, sondern weil die Classifier-Grenzen sich verschoben haben. Dieselbe Seite, derselbe Text, ein anderer Score — und damit eine andere Klassifikation.
Pipeline-Zuordnung: Der Sprung entsteht auf Classifier-Ebene. Ein Core Update verschiebt die Schwellenwerte oder die Signalgewichtung in den Quality-Classifiern — der SegIndexer stuft das Dokument in ein anderes Tier ein. Der Sprung ist abrupt, weil die Klassifikation binär wirkt: im Pool oder nicht im Pool, Base-Tier oder Zeppelins-Tier. Die Relevanzbewertung durch Mustang und die Nutzersignale über NavBoost ändern sich dabei nicht — nur die Zugangsberechtigung zum Ranking-Pool.
Muster 3: Impressionen steigen, Klicks divergieren — der stille Relevanzverlust
Ein subtileres, aber analytisch betrachtet wichtiges Muster: Die Impressionenkurve steigt oder bleibt stabil, aber die Klickkurve fällt oder stagniert. Die beiden Kurven, die normalerweise parallel laufen, driften auseinander.
Hier gibt es zwei verschiedene Ursachen, die sich in der GSC allein nicht definitiv trennen lassen, aber mit dem Pipeline-Wissen eingrenzen:
Ein CTR-Problem bei stabiler Position. Deine Rankings sind stabil, aber die Klickrate sinkt. Das kann passieren, weil ein Wettbewerber ein Featured Snippet gewonnen hat (zumindest vor dem Start der AI Overviews) oder aber eben weil jene AI Overviews den Klickbedarf direkt in den Suchergebnissen befriedigen. Es gibt weitere Möglichkeiten: zum Beispiel weil deine Title-Tags nicht mehr zum veränderten Suchverhalten passen. AI Overviews sind dabei besonders tückisch: Die GSC trennt AI-Overview-Impressionen nicht von regulären Impressionen. Du siehst die Impression, aber der Klick geht an niemanden — weil der Nutzer seine Antwort bereits oberhalb der organischen Ergebnisse erhalten hat.
Ein Wechsel der Suchintention. Google rankt deine Seite weiterhin. Deswegen bekommst du Impressionen, aber die Suchintention hat sich verändert. Nutzer suchen dasselbe Keyword, erwarten aber einen anderen Seitentyp. Dein Dokument wird gezeigt, aber nicht geklickt — oder angeklickt und sofort wieder verlassen, was über NavBoost die Position langfristig verschlechtern kann.
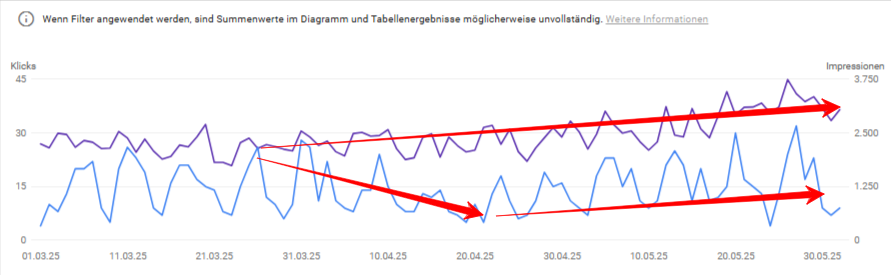
Die GSC liefert Hinweise zur Eingrenzung: Wenn die CTR für ein Keyword von 8% auf 3% gefallen ist, die Position aber stabil geblieben ist, deutet das auf das CTR-Problem. Wenn gleichzeitig die durchschnittliche Position sich verschlechtert hat und die Impressionen trotzdem gestiegen sind, deutet das eher auf eine Erweiterung des Keyword-Profils in Bereiche, in denen du schlechter rankst — was wiederum ein anders geartetes Problem ist.
Pipeline-Zuordnung: Das CTR-Problem liegt außerhalb der Pipeline — es ist ein SERP-Level-Effekt (Featured Snippets, AI Overviews, Wettbewerber-Snippets). Der Wechsel der Suchintention betrifft die Relevanz-Ebene: Mustangs T*-Bewertung passt noch, aber die Nutzersignale über NavBoost verschlechtern sich, weil die Nutzererwartung sich verändert hat. Beide Ursachen führen zum selben GSC-Bild — was die Diagnose erschwert.
Muster 4: Die Neutralisierung — was passiert, wenn nichts passiert
Nicht jedes GSC-Muster ist dramatisch. Eines der aufschlussreichsten ist die Stagnation: eine Kurve, die über Monate weder steigt noch fällt, sondern in einem gleichmäßigen Seitwärtsmuster verharrt.
Auf den ersten Blick sieht das stabil aus. Auf den zweiten Blick ist es ein Warnsignal. Denn die Re-Ranking-Zyklen aus Muster 1 hören nicht auf, nur weil du aufhörst zu publizieren. Google testet weiter. NavBoost sammelt weiter Nutzerdaten. Konkurrenten veröffentlichen weiter Inhalte. Classifier werden weiter rekalibriert. Wenn deine Website in dieser Umgebung weder steigt noch fällt, bedeutet das, dass die positiven Signale — bestehende Inhalte, historische Nutzerdaten — gerade ausreichen, um die zunehmende Konkurrenz und die Rekalibrierungen zu kompensieren. Aber nicht, um zu wachsen.
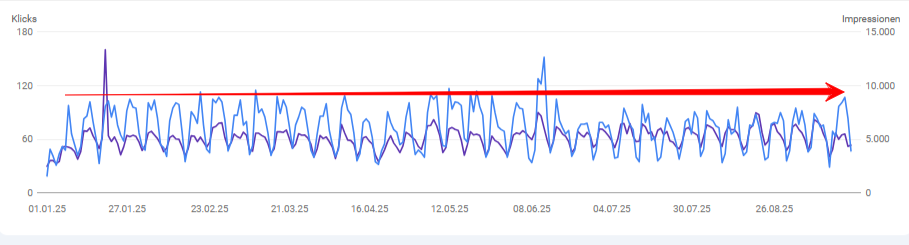
Koray nennt diesen Zustand „Neutralisierung“ und beobachtet ihn typischerweise bei Projekten, die die Content-Produktion und -Aktualisierung eingestellt haben. Die Website lebt von ihrem Bestand. Solange kein Core Update kommt, das die Schwellenwerte verschiebt, bleibt sie auf ihrem Plateau. Aber sie hat keinen Puffer — jede Rekalibrierung nach oben durch einen Konkurrenten oder nach unten durch ein Update kann das Gleichgewicht kippen.
In der GSC erkennst du dieses Muster daran, dass Klicks und Impressionen über mindestens drei bis vier Monate in einem engen Band schwanken, ohne dass ein Aufwärts- oder Abwärtstrend erkennbar ist — und ohne dass du in diesem Zeitraum wesentlich neue Inhalte publiziert oder bestehende aktualisiert hast.
Pipeline-Zuordnung: Neutralisierung ist ein Gleichgewichtszustand über alle Pipeline-Stufen hinweg. Die Classifier-Einstufung ist stabil, die NavBoost-Daten zeigen keine Verschlechterung (aber auch keine Verbesserung), die Twiddler-Adjustierungen pendeln um einen Mittelwert. Der Zustand ist sozusagen „metastabil“ — er hält, solange sich die externen Bedingungen nicht ändern. Ein Core Update, ein neuer starker Konkurrent oder eine technische Verschlechterung kann das Gleichgewicht jederzeit kippen.
Muster 5: Das V und die Nicht-Erholung — Signal Dilution
Das letzte Muster betrifft nicht den natürlichen Verlauf, sondern Fehler: Ein plötzlicher Einbruch, geformt wie ein V, der mit einem technischen Ereignis korreliert. Ein Relaunch, bei dem versehentlich die gesamte Website dupliziert wurde. Filter-Einstellungen in Online-Shops, die tausende unnötige URLs erzeugen. Ein CMS-Update, das Redirect-Ketten bricht.
In der GSC sieht das aus wie ein scharfer Einbruch — manchmal 50% oder mehr innerhalb weniger Wochen. Der entscheidende Punkt ist nicht der Einbruch selbst, sondern was danach passiert: Wenn das Problem schnell behoben wird — Duplikate entfernt, Redirects repariert, unnötige URLs aus dem Index genommen —, folgt oft eine Erholung. Das V vervollständigt sich. Wenn das Problem aber über Wochen oder Monate bestehen bleibt, kann die Erholung ausbleiben oder unvollständig sein.
Warum? Weil Google in dieser Zeit weiter crawlt, weiter testet und weiter bewertet. Jeder Crawl, bei dem der Googlebot auf unnötige, duplizierte oder fehlerhafte Seiten trifft, ist ein Signal — nicht das einzelne Signal, aber die Akkumulation. Die Crawler-Ressourcen, die Google in deine Website investiert, werden auf tausende wertlose URLs verteilt statt auf die Seiten, die tatsächlich ranken sollten. Anderson beschreibt aus dem API-Leak, dass Googles Crawling-System Trawler die Crawl-Frequenz auf Basis von Seitenänderungen steuert. Wenn plötzlich tausende neue URLs auftauchen, reagiert das System — und die Bewertung der Gesamtsite kann sich verschieben.
Koray verwendet dafür den Begriff „Ranking Signal Dilution“: Die Signale, die Google über eine Website sammelt, werden auf alle URLs verteilt. Je mehr unnötige URLs existieren, desto dünner werden die Signale pro relevanter URL. Googles eigene Terminologie spricht eher von Crawl-Budget-Verschwendung — aber das Ergebnis ist operativ dasselbe: Die relevanten Seiten werden seltener gecrawlt, seltener bewertet und verlieren an Sichtbarkeit.
In der GSC erkennst du dieses Problem an zwei Stellen gleichzeitig: einem plötzlichen Klick-Einbruch im Performance-Report, der mit einer technischen Änderung korreliert — und einem Anstieg der „Gecrawlt, aber nicht indexiert“-Seiten oder der 404-Fehler in den Coverage-Reports.
Pipeline-Zuordnung: Signal Dilution betrifft die früheste Stufe — noch vor Mustang. Wenn Trawler Crawl-Budget auf wertlose URLs verteilt, werden die relevanten Seiten seltener gecrawlt und seltener im Index aktualisiert. Die Classifier-Bewertung kann sich verschlechtern, weil site-weite Signale wie siteAuthority durch die Masse an schwachen URLs nach unten gezogen werden. Und NavBoost verliert an positiver Datenbasis, weil die relevanten Seiten weniger Impressionen bekommen und damit weniger Klickdaten produzieren — ein Teufelskreis.
Diese fünf Muster sind keine vollständige Taxonomie. Sie sind die wiederkehrenden Formationen, die sich über verschiedene Projekte hinweg zeigen und die sich über die dokumentierte Pipeline erklären lassen. Was sie gemeinsam haben: Sie sind aus den GSC-Daten ablesbar, zumindest wenn du weißt, wonach du suchst.
Im nächsten Abschnitt zeige ich, wie du diese Muster mit KI-gestützten Werkzeugen systematisch identifizieren kannst — und warum die Wahl des Werkzeugs weniger wichtig ist als die Frage, die du stellst.
Die richtigen Fragen stellen — drei Werkzeuge, drei Ebenen
Du kennst jetzt die Pipeline und die Muster, die sie in GSC-Daten hinterlässt. Was bisher fehlt, ist der praktische Zugang: Wie überführst du dieses Wissen in Abfragen, die dir die Muster in deinen eigenen Daten zeigen?
Bis vor Kurzem war die Antwort: manuell. GSC öffnen, Filter setzen, Datumsvergleich konfigurieren, exportieren, weiterverarbeiten, Fragen formulieren, Analyse starten, wieder von vorne. Das funktioniert, aber der Prozess ist langsam genug, dass die meisten SEOs diesen Ablauf nicht regelmäßig operativ beschreiten, sondern eher flüchtig draufschauen und intuitiv bewerten. Und genau das ist das Problem. Doch es gibt Abhilfe. Sogar gleich zwei davon.
Googles KI-Konfiguration — schneller filtern
Seit Februar 2026 können alle GSC-Nutzer im Performance-Report natürlichsprachliche Abfragen eintippen. Statt manuell Filter, Datumsvergleiche und Metriken zu konfigurieren, beschreibst du, was du sehen willst: „Zeig mir Queries auf Mobilgeräten mit dem Wort „SEO“ in den letzten sechs Monaten.“ Die KI konfiguriert den Report automatisch.
Das ist ein realer Effizienzgewinn. Filter setzen, Datumsräume vergleichen, Metriken auswählen, Keywords nach Muster filtern — alles, was du vorher durch die Oberfläche geklickt hast, funktioniert jetzt per Texteingabe. Für operative Standardfragen ist das schneller und bequemer.
Aber es bleibt ein Report-Konfigurator. Was du bekommst, ist derselbe Report, den du vorher manuell zusammengeklickt hast — nur schneller. Die KI filtert, gruppiert und vergleicht innerhalb der vorhandenen Dimensionen des Performance-Reports. Sie berechnet keine abgeleiteten Metriken. Sie wendet kein analytisches SEO-Wissen an. Sie arbeitet ausschließlich im Performance-Report für Suchergebnisse — nicht im Indizierungsbericht, nicht in den Crawl-Statistiken, nicht reportübergreifend.
Für die Frage „Zeig mir Keywords mit hohen Impressionen und niedriger CTR“ ist das das richtige Werkzeug. Für die Frage „Befindet sich meine Website in einem negativen Ranking-Zyklus?“ nicht.
MCP — analysieren statt filtern
Eine grundlegend andere Möglichkeit bietet das Model Context Protocol. Suganthan Mohanadasan hat einen Open-Source-MCP-Server gebaut, der Claude Desktop direkt mit der Google Search Console API verbindet. Die Einrichtung dauert etwa 15 Minuten, kostet nichts und läuft lokal — deine Daten verlassen deinen Rechner nicht. Wer die Einrichtung Schritt für Schritt nachvollziehen will, findet in Suganthans Artikel eine vollständige Anleitung.
Der entscheidende Unterschied zur GSC-KI ist nicht, dass Claude mehr Daten sieht. Es sieht dieselben Daten — die GSC-API liefert dieselben Informationen, auf denen auch Googles eigene KI arbeitet. Der Unterschied ist, was Claude mit den Daten tun kann: Du kannst ihm ein bzw. dein eigenes SEO-Framework, deine eigene Methodik mitgeben und Claude bitten, dieses Framework auf deine Daten anzuwenden.
Statt „Zeig mir Keywords mit Klickverlusten“ kannst du fragen:
„Analysiere meine GSC-Daten der letzten 12 Monate auf Anzeichen eines negativen Ranking-Zyklus. Prüfe drei Dinge: Erstens, ob die durchschnittliche Position meiner Top-50-Seiten sich in den letzten drei 28-Tage-Perioden jeweils verschlechtert hat. Zweitens, ob Seiten, die in den letzten 90 Tagen erstmals Impressionen erhalten haben, mit einer schlechteren durchschnittlichen Position starten als Seiten, die vor 6 Monaten erstmals aufgetaucht sind. Drittens, ob der Anteil der indizierten Seiten mit null Impressionen gestiegen ist.“
Das ist kein Filter. Das ist eine Teilanalyse — eine, die ein konzeptionelles Framework auf Daten anwendet und eine strukturierte Diagnose zurückliefert. Die GSC-KI kann das nicht.
Und hier wird das Wissen aus den ersten beiden Abschnitten in etwas Operatives überführt. Denn die Qualität von Claudes Analyse hängt direkt davon ab, wie präzise du das Framework bzw. dein Wissen in die Frage einbaust. Claude weiß grob, was ein Ranking-Zyklus ist und kann sich dies herleiten, aber die KI weiß nicht, worauf du hinaus willst, wovon du konkret sprichst. Claude weiß nicht, dass die initiale Position neuer Inhalte ein zentrales Signal ist, es sei denn, du formulierst die Prüfung explizit. Das Werkzeug ist mächtig. Aber es ist genau so mächtig wie die Frage, die du stellst. Einer KI eine eigene Knowledge Base mitzugeben, den richtigen Kontext bereitzustellen, das ist übrigens eine Prompting-Technik namens „Generated Knowledge“.
Die analytischen Fragen und was sie prüfen
Was folgt, sind keine Einzelfilter, sondern auf Analyseerkenntnis abzielende Gesamtfragen, die jeweils ein Muster aus dem vorherigen Abschnitt prüfen, formuliert als Prompt, den du Claude über den MCP-Server stellen kannst. Ich habe sie mit den GSC-Daten eines deutschen E-Commerce-Shops getestet.
Diagnose 1 — Ranking-Zyklus bestimmen (Muster 1 und 4)
„Analysiere die Entwicklung meiner Website über die letzten 12 Monate. Teile den Zeitraum in sechs 2-Monats-Perioden und zeig mir für jede Periode: Gesamtklicks, Gesamtimpressionen, durchschnittliche CTR und die durchschnittliche Position der Top-50-Seiten nach Klicks. Zeigt der Trend eine aufsteigende Treppe — jede Periode besser als die vorherige mit temporären Rückgängen dazwischen? Oder eine Seitwärtsbewegung? Oder einen Abwärtstrend? Zeig mir die Daten als Tabelle.“
Was du damit herausfindest: Ob deine Website sich in einem positiven, neutralen oder negativen Ranking-Zyklus befindet. Die Treppenformation zeigt einen positiven Zyklus. Seitwärtsbewegung über mehrere Perioden zeigt Neutralisierung. Ein konsistenter Abwärtstrend trotz fortlaufender Veröffentlichung zeigt einen negativen Zyklus.
Was im Test passiert ist: Claude hat die Daten korrekt in Perioden aufgeteilt und als Tabelle geliefert. Allerdings reichte das GSC-Datenfenster (16 Monate) nur für drei vollständige Perioden statt sechs — und Claude hat aus drei Datenpunkten bereits eine „aufsteigende Treppe“ diagnostiziert. Das ist voreilig: Drei Perioden reichen nicht, um ein Treppenmuster belastbar von normalem Wachstum zu unterscheiden. Die Datenstrukturierung funktioniert. Die Diagnose muss der Mensch übernehmen, und zwar immer mit der nötigen Skepsis gegenüber kleinen Stichproben.
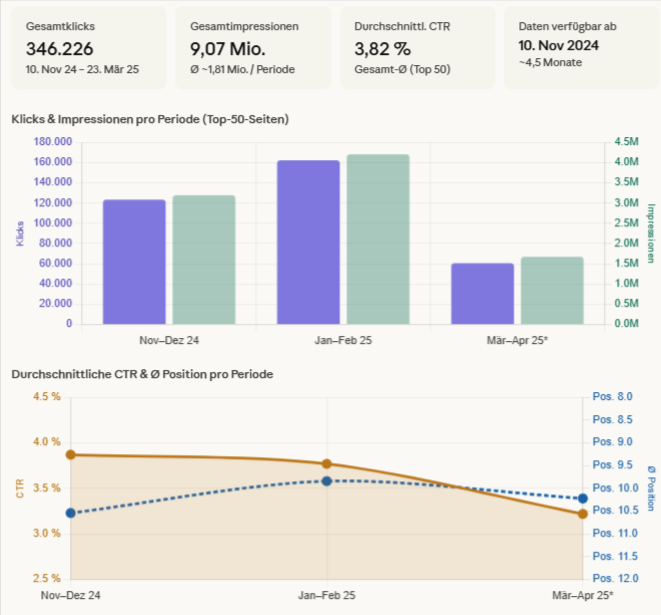
Praxis-Erkenntnis: Das 16-Monate-Datenfenster der GSC ist für diese Diagnose eine reale Einschränkung. Sechs 2-Monats-Perioden erfordern 12 Monate — das funktioniert gerade noch. Wer aber den Verlauf über Core Updates hinweg vergleichen will, die mehr als 16 Monate zurückliegen, braucht regelmäßige Datenexporte in ein externes System. Ohne historische Tiefe ist die Diagnose „Ranking-Zyklus“ methodisch dünn.
Diagnose 2 — Core-Update-Auswirkung lokalisieren (Muster 2)
„Vergleiche die Perioden [vor dem Update, z.B. Oktober–Dezember 2025] und [nach dem Update, z.B. Januar–März 2026]. Identifiziere alle Keywords, die in der ersten Periode mindestens 100 Impressionen hatten, in der zweiten Periode aber mehr als 50% ihrer Klicks verloren haben. Gruppiere diese Keywords nach den URLs, auf denen sie ranken. Gibt es URLs, auf denen sich die Verluste konzentrieren — und gibt es gleichzeitig URLs, die stabil geblieben oder gewachsen sind?“
Was du damit diagnostizierst: Ob ein Core Update deine Website pauschal getroffen hat oder clusterspezifisch. Wenn die Verluste auf wenige URLs konzentriert sind und der Rest stabil ist, hast du ein lokales Problem, vermutlich eine Classifier-Neubewertung in einem bestimmten Themenfeld. Wenn die Verluste breit gestreut sind, ist es ein site-weites Problem. Diese Unterscheidung bestimmt, ob du punktuell nachbesserst oder strukturell.
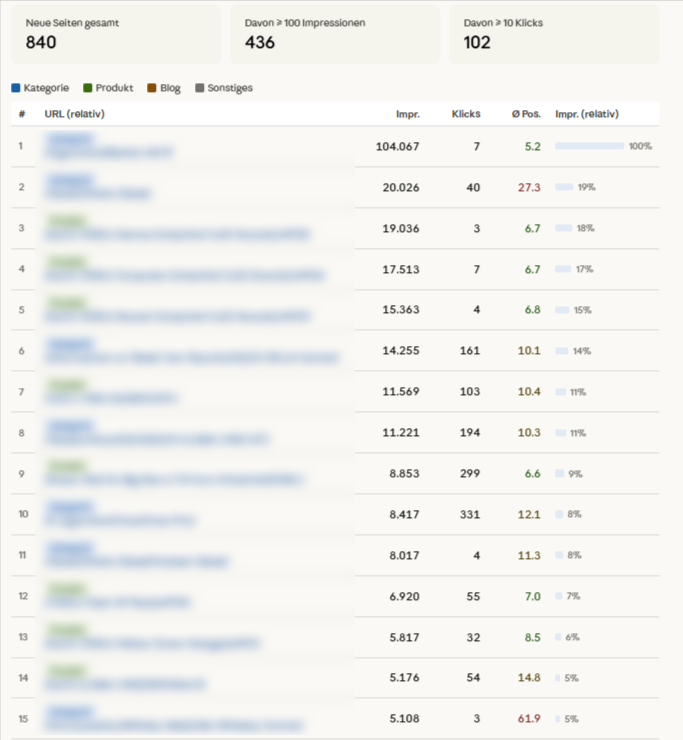
Für die tiefere Analyse, also ob die verlorenen Keywords auch thematisch zusammengehören und nicht nur zufällig auf denselben Seiten liegen, stößt die reine GSC-Abfrage an ihre Grenzen. Dort setzt die Embedding-Methode aus meinem letzten Artikel an, die das gesamte Keyword-Set in einen Vektorraum projiziert und thematische Cluster sichtbar macht.
Diagnose 3 — Signal Dilution aufspüren (Muster 5)
„Wie viele meiner Seiten, die in den letzten 6 Monaten mindestens eine Impression hatten, haben in diesem Zeitraum null Klicks erhalten? Nenne mir die Gesamtzahl und den prozentualen Anteil. Zeig mir außerdem Beispiele von Seiten mit null Klicks, die trotzdem eine durchschnittliche Position besser als 15 haben — also Seiten, die gut ranken, aber niemand anklickt.“
Was du damit diagnostizierst: Den Anteil deiner Website, den Google zwar ausspielt, der aber keinen einzigen Klick erzeugt. Jede dieser Seiten verbraucht Crawl-Budget, ohne etwas beizutragen. Ein geringer prozentualer Anteil ist okay und völlig normal, besonders bei größeren Seiten. Ein deutlich höherer Anteil ist ein Warnsignal.
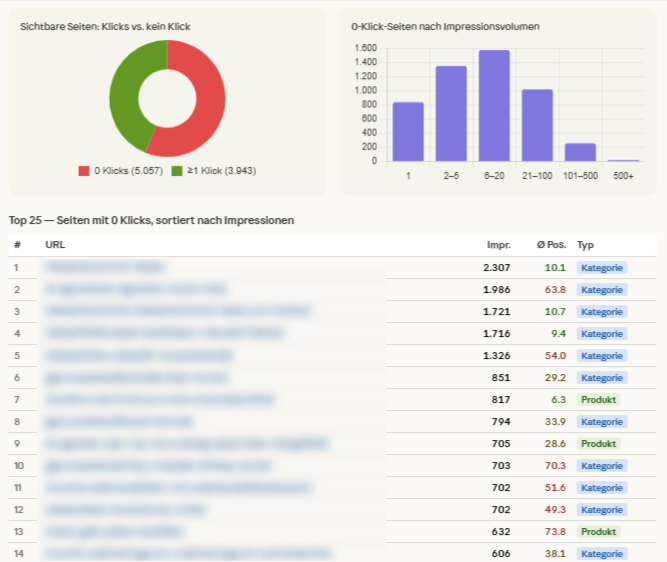
Was im Test passiert ist: Claude identifizierte 5.057 Seiten mit null Klicks — 56,2% aller sichtbaren Seiten. Ein außergewöhnlich hoher Anteil. Darunter Kategorieseiten mit guter Position (Position 10, über 2.000 Impressionen, null Klicks), Produktseiten auf Position 6 ohne einen einzigen Klick, und eine indizierte interne Suchseite, die nicht im Index sein sollte. Jede dieser Seiten ist ein konkreter Handlungspunkt — Snippet-Optimierung, Noindex-Tag, oder die Frage, ob die Seite überhaupt existieren muss.
Praxis-Erkenntnis: Die GSC-API kann keine Seiten zurückgeben, die null Impressionen haben — also komplett unsichtbare URLs. Für die vollständige Signal-Dilution-Diagnose müsstest du den Indexierungsbericht (Coverage-Report) mit den Performance-Daten abgleichen, was über die API derzeit nicht möglich ist. Was die API liefert, ist der sichtbare Teil des Problems: Seiten, die Google ausspielt, die aber niemand anklickt. Das ist bereits diagnostisch wertvoll — aber es ist eine Untergrenze, nicht das vollständige Bild.
Was die Prompts zeigen und was sie nicht zeigen
Die drei Diagnosen illustrieren das Muster, das sich durch diesen gesamten Artikel zieht: Das Werkzeug ist genau so gut wie die Frage, die du stellst. Und die Frage ist genau so gut wie dein Verständnis davon, was in den Daten sichtbar sein kann und was nicht.
Claude kann erkennen, was passiert. Die durchschnittliche Position verschlechtert sich über drei Perioden. Die Verluste nach einem Core Update konzentrieren sich auf fünf URLs. 56% der sichtbaren Seiten erzeugen null Klicks. Das ist Mustererkennung auf Basis von Daten — und sie ersetzt Stunden manueller Arbeit.
Was Claude nicht kann, ist das Warum zu beantworten. Liegt der negative Zyklus an einer Classifier-Rekalibrierung nach einem Core Update? An einem Konkurrenten, der in genau diesem Themenfeld massiv publiziert hat? An einer internen Verlinkungsstruktur, die nach einem Relaunch gebrochen ist? An einer Verschiebung der primären Suchintention von informationell zu kommerziell, der für deine Kern-Keywords jetzt einen anderen Seitentyp bevorzugt? Diese Fragen erfordern Kontextwissen, das nicht in den GSC-Daten steckt: deine Veröffentlichungshistorie, mögliche technischen Änderungen, die Aktivitäten deiner Wettbewerber usw.
Claude hat darauf keinen Zugriff (außer du informierst die KI darüber). Und selbst wenn Claude ihn hätte — die Verbindung zwischen dem Datenmuster und der richtigen Pipeline-Stufe ist die Arbeit, für die du ein Verständnis von Googles Ranking-Mechanik brauchst. Kein Tool nimmt dir das zuverlässig und vollständig ab.
Suganthan hat in Version 1.1.0 seines MCP-Servers Guardrails eingebaut, die Claude anweisen, sich auf die tatsächlichen Daten zu stützen und bei Ursachenfragen „Ich weiß es nicht“ zu sagen statt zu spekulieren. Zusätzlich liefert jede Antwort ein _meta-Feld, das die Datenquelle dokumentiert, und ein verify_claim-Tool ermöglicht es Claude, eigene Aussagen gegen die API gegenzuprüfen. Das reduziert das Halluzinationsrisiko. Es eliminiert es nicht. Im Test hat Claude bei Diagnose 1 aus drei Datenpunkten einen positiven Trend diagnostiziert — fachlich voreilig, aber überzeugend formuliert. Wer die Ergebnisse ungeprüft übernimmt, wird, wie immer bei KI-Einsatz, womöglich bald unschöne Folgen erleben müssen.
Die Arbeitsteilung ist damit klar: Die GSC-KI beschleunigt die Bedienung. Der MCP macht Claude zum Analysten, der vorgegebene Frameworks auf Daten anwenden kann. Und du bist der SEO-Analyst, der die Ergebnisse in den Kontext setzt und entscheidet, was zu tun ist.
Wo die Analyse an ihre Grenzen stößt
Drei Einschränkungen möchte ich hervorheben, die du selbst mit hoher Prompt-Qualität nicht ausgleichen kannst:
Die GSC-Daten selbst sind lückenhaft
Selbst eine perfekte Analyse kann nur so gut sein wie die Daten, die eingehen. Die Einschränkungen aus dem ersten Abschnitt — Sampling, anonymisierte Suchanfragen, das 16-Monate-Fenster, die fehlende Trennung von AI-Overview-Impressionen, das API-Limit von 50.000 Zeilen — gelten für jedes Werkzeug gleichermaßen. Weder Googles KI-Konfiguration noch der MCP-Server noch die Embedding-Methode können Daten analysieren, die Google nicht liefert.
Eine konkrete Konsequenz: Wenn du analytische Fragen über Long-Tail-Keywords stellst, arbeitest du mit einer Datenbasis, die laut der ZipTie-Analyse etwa die Hälfte des tatsächlichen Long-Tail-Traffics nicht enthält. Deine Diagnose ist dann korrekt für die sichtbaren Daten, aber möglicherweise nicht repräsentativ für das Gesamtbild.
Cross-Report-Analysen sind eingeschränkt
Der MCP-Server greift auf die Google Search Console API zu. Der Performance-Report (über den searchAnalytics-Endpunkt) und die URL-Inspektion sind darüber zugänglich. Die Crawl-Statistiken und der vollständige Coverage-Report sind über diese API derzeit nicht oder nur eingeschränkt abfragbar.
Für thematische Muster brauchst du ein anderes Werkzeug
Wenn du wissen willst, ob die Verluste nach einem Core Update thematisch geclustert sind — ob Google in bestimmten Themenfeldern anders entscheidet als in anderen —, stößt die GSC-Abfrage an eine strukturelle Grenze. Die GSC zeigt dir Keywords mit Klick- und Positionsveränderungen. Sie zeigt dir nicht, ob diese Keywords semantisch zusammengehören.
Du kannst Claude bitten, die verlorenen Keywords nach URL zu gruppieren — das hilft, wenn verschiedene Themenfelder auf verschiedenen URLs liegen. Aber wenn mehrere Themen auf einer URL behandelt werden oder wenn das thematische Muster quer über URLs verläuft, kommst du mit URL-Gruppierung nicht weiter.
Die Embedding-Analyse aus meinem letzten Artikel löst genau dieses Problem. Sie projiziert die Keywords in einen Vektorraum, in dem semantische Nähe als räumliche Nähe sichtbar wird. Verlorene Keywords, die in derselben Region des Vektorraums clustern, deuten auf eine themenspezifische Verschiebung — ein Muster, das in keiner Tabelle auftaucht, egal wie intelligent die Abfrage formuliert ist.
Fazit
Die Google Search Console liefert die Daten, die du für eine fundierte Ranking-Diagnose brauchst. Aber die Daten allein sind kein Befund — so wenig wie ein Blutbild eine Diagnose ist.
Was die Daten diagnostisch lesbar macht, ist das Verständnis der Mechanik dahinter. Googles Ranking-Pipeline — Retrieval über Mustang, Klassifikation über Quality-Classifier, Re-Ranking über Twiddler und NavBoost, finale Bewertung über Machine-Learning-Modelle — hinterlässt spezifische Spuren in den GSC-Daten: die Treppenformation eines positiven Ranking-Zyklus. Der Sprung nach einem Core Update, wenn ein Classifier-Schwellenwert überschritten wird. Die Divergenz zwischen Impressionen und Klicks, wenn sich die SERP-Struktur und -Logik verändert. Die Stagnation, die eintritt, wenn eine Website aufhört zu publizieren.
Die Werkzeuge dafür sind jetzt zugänglich. Googles KI-Konfiguration beschleunigt die Bedienung der Search Console. MCP-Server wie der von Suganthan Mohanadasan machen Claude zum Analysten, der deine Frameworks auf GSC-Daten anwenden kann. Embedding-basierte Methoden machen thematische Verschiebungen sichtbar, die in keiner Tabelle erscheinen. Drei Werkzeuge, drei Ebenen: Bedienung, Analyse, Visualisierung.
Aber kein Werkzeug ersetzt die Frage, die du stellst. Und keine Analyse ersetzt das Urteil, das du fällst. Der Engpass war nie der Zugang zu den Daten. Der Engpass liegt meist im Wissen, was die Daten bedeuten.
Über diesen Artikel
Die inhaltliche Verantwortung für jeden Artikel auf diesem Blog liegt bei mir, Patrick Stolp. Thema, These, Recherche und fachliche Prüfung sind meine Arbeit – hier wird nichts veröffentlicht, das ich nicht selbst konzipiert, geschrieben und als korrekt verifiziert habe. Generative KI (Claude von Anthropic) kommt punktuell als Werkzeug zum Einsatz – etwa für Formulierungsentwürfe oder das Gegenlesen technischer Erklärungen. Kein KI-Output landet ungeprüft oder unverändert auf dieser Seite. Beitragsbilder werden mit Google Nano Banana 2 erstellt.
Mehr dazu in meinen Redaktionsrichtlinien.