Sichtbarkeit in der KI-Suche messen: Warum Rankings nicht funktionieren

Zwei KPIs, eine unbequeme Wahrheit
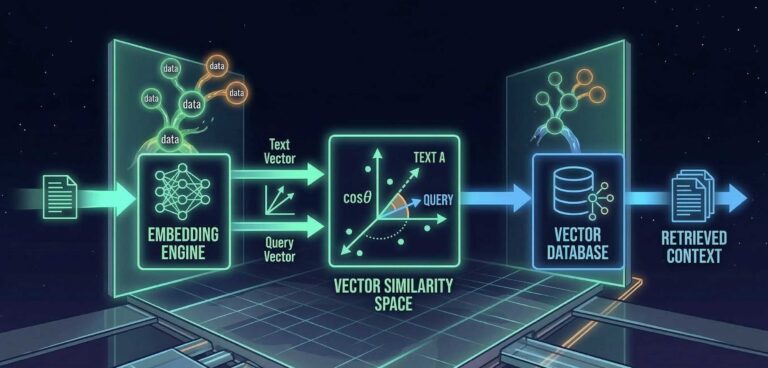
In meinem letzten Artikel habe ich erklärt, wie Vektoren, Chunks, Query Fan-out, kurzum: die KI-Suche unter der Haube funktioniert. Wir wissen, dass GEO eine Teilmenge von SEO ist und dass sich Optimierung für beide Disziplinen lohnt. Bleibt die naheliegende Folgefrage: Wie messe ich eigentlich, ob das funktioniert?
In der klassischen Suche ist die Antwort simpel. Du trackst Rankings, Klickraten, organischen Traffic – fertig. Tools wie Sistrix oder Ahrefs liefern dir tagesaktuelle Daten, und wenn du von Position 8 auf Position 3 steigst, weißt du: läuft. In der KI-Suche gibt es diesen Luxus nicht.
Was sich messen lässt, sind grundsätzlich zwei Dinge. Erstens: Brand Mentions – wird deine Marke in der KI-Antwort namentlich genannt? Also empfiehlt ChatGPT „Check24″, wenn jemand nach einer SEO-einem Autokredit fragt?
Zweitens: URL-Citations – wird deine Webseite als Quellenbeleg unter der Antwort verlinkt? Beides sind legitime KPIs, und auf den ersten Blick klingt das Tracking danach genauso machbar wie bei Google-Rankings.
Auf den zweiten Blick sieht die Sache allerdings völlig anders aus. Denn es gibt ein fundamentales Problem, das die gesamte Messlogik aus der SEO-Welt aushebelt, und das die meisten GEO-Tools geflissentlich verschweigen.
Warum KI-Antworten nicht reproduzierbar sind
Um das Problem zu verstehen, müssen wir kurz zurück zu den vier Phasen aus dem letzten Artikel. Crawling, Indizierung und Anfrageverarbeitung laufen bei Google und KI-Chatbots fast identisch ab. Aber bei der Ausgabe – also dem, was am Ende beim Nutzer ankommt – trennen sich die Wege. Und zwar grundlegend.
Google ist deterministisch. Das bedeutet: Gleiche Suchanfrage, gleicher Ort, gleiches Gerät, gleicher Zeitpunkt – immer dasselbe Ergebnis. Wenn du jetzt „Autokredit“ googelst und ich im selben Moment dasselbe tue, sehen wir die gleiche Liste: ING auf Platz 1, Check24 auf Platz 2, Smava auf Platz 3. Morgen vielleicht anders, aber in diesem Moment: identisch. Die Ergebnisliste existiert im Index – Google ruft sie ab, sortiert und zeigt sie an. Nichts wird in Echtzeit „erfunden“.
KI-Chatbots sind probabilistisch. Hier existiert keine fertige Liste. Die Antwort wird Token für Token generiert – Wort für Wort, wenn man so will. Und bei jedem einzelnen Token spielt ein Zufallsfaktor mit. Die KI berechnet Wahrscheinlichkeiten für das nächste Wort, wählt aber nicht immer das wahrscheinlichste. Stell dir das wie einen gewichteten Würfel vor: Die Sechs fällt häufiger als die Eins, aber eben nicht jedes Mal.
In der Praxis heißt das: Du stellst ChatGPT dreimal hintereinander die Frage „Welchen Autokredit-Anbieter empfiehlst du?“ – und bekommst dreimal eine andere Antwort. Durchlauf 1: ING, Smava, Check24. Durchlauf 2: Check24, Verivox. Durchlauf 3: Smava, ING, Santander. Gleiche Frage, gleicher Zeitpunkt, gleicher Nutzer, aber die Reihenfolge, die Auswahl, teilweise sogar die Anzahl der Nennungen variiert.
Wer jetzt denkt „Na gut, ein bisschen Variation, aber im Kern wird schon dasselbe rauskommen“ – den muss ich leider enttäuschen. Denn die Inkonsistenz ist nicht marginal. Sie ist massiv.
Die Zahlen: Wie inkonsistent KI wirklich ist
SparkToro hat genau das getan, was die meisten GEO-Tool-Anbieter lieber nicht tun würden: Sie haben 2.961 identische Prompts mehrfach an ChatGPT und Claude geschickt und ausgewertet, wie oft dasselbe Ergebnis rauskommt. Die Zahlen sind ernüchternd.
In weniger als 1 % der Fälle lieferte die KI eine identische Empfehlungsliste, also dieselben Marken oder Produkte. Die Wahrscheinlichkeit, dass auch die Reihenfolge übereinstimmt, lag bei unter 0,1 %. Nur 9,2 % der Quellen-URLs blieben über drei Durchläufe stabil. Und in jedem fünften Durchlauf, also 21,2 %, gab es null Überschneidung. Keine einzige URL, die in beiden Durchläufen auftauchte.
Lass dir das kurz auf der Zunge zergehen. Wenn du ein GEO-Tool nutzt, das einmal am Tag den Prompt „bester Autokredit“ an ChatGPT schickt und dir meldet, deine Marke stehe auf „Platz 2″, dann ist diese Information mit einer Wahrscheinlichkeit von über 99 % nicht reproduzierbar. Kein anderer Nutzer, der denselben Prompt eingibt, wird dasselbe sehen. Du trackst eine Momentaufnahme. Einen einzelnen Würfelwurf. Und zahlst dafür vermutlich eine monatliche Lizenzgebühr.
Das soll nicht heißen, dass Sichtbarkeit in KI-Antworten irrelevant ist. Ganz im Gegenteil. Aber die Art, wie die SEO-Branche versucht, Ranking-Logik auf ein probabilistisches System zu übertragen, funktioniert schlicht nicht. Einzelne Positionen tracken in einem System, das keine festen Positionen kennt, das klingt für mich unsinnig.
Der Kontextraum: Die KI würfelt nicht blind
Jetzt könnte man fragen: Wenn alles so zufällig ist, warum dann überhaupt optimieren? Berechtigte Frage. Die Antwort liegt im Kontextraum.
Die KI würfelt zwar bei jedem Token neu, aber sie würfelt innerhalb eines begrenzten Raums. Nur Marken, Produkte und Quellen, die das Modell mit einem bestimmten Thema assoziiert, können überhaupt in der Antwort auftauchen. Beim Prompt „Autokredit“ sind das Check24, Verivox, ING, Smava, Santander, die Sparkasse und vielleicht noch eine Handvoll weiterer Anbieter. Lieferando wird nie erscheinen. Auch nicht ein einziges Mal unter Tausend Durchläufen.
Der Kontextraum ist im Grunde die Menge aller Entitäten, die die KI durch ihre Trainingsdaten und RAG-Quellen mit einem Thema verknüpft hat. Wer in diesem Raum ist, hat bei jedem Würfelwurf eine Chance, genannt zu werden. Wer nicht drin ist, existiert für die KI schlicht nicht.
Und genau das macht Optimierung trotz aller Inkonsistenz sinnvoll. Das Ziel ist nicht, auf „Platz 1 in ChatGPT“ zu landen. Das Ziel ist, überhaupt im Kontextraum zu sein und dort eine möglichst hohe Wahrscheinlichkeit zu haben, bei einem gegebenen Thema genannt zu werden. Ob du bei einem einzelnen Durchlauf auf Position 2 oder Position 5 stehst, ist irrelevant. Ob du in 70 % oder in 20 % aller Durchläufe überhaupt auftauchst, ist die entscheidende Frage.
Hyperkontextualisierung: Warum es noch komplizierter wird
Bisher haben wir uns nur mit dem Fall beschäftigt, dass Nutzer wortgleiche Prompts eingeben. In der Realität passiert das so gut wie nie. Denn KI-Chatbots laden geradezu dazu ein, individuelle Kontexte mitzugeben. Und genau das tun Nutzer auch.
Ein Beispiel. Drei Personen wollen geräuschunterdrückende Kopfhörer kaufen. Gleiche Absicht, gleiches Produkt. In der klassischen Google-Suche würden alle drei etwas wie „noise cancelling kopfhörer test“ eingeben, vielleicht mit leichten Variationen. Die Ergebnisse wären nahezu identisch.
In einem KI-Chatbot sieht das völlig anders aus:
- „Ich fliege nächste Woche nach Japan und brauche Kopfhörer, die im Flugzeug gut funktionieren. Budget bis 300 €.“
- „Welche Over-Ear-Kopfhörer haben das beste ANC? Ich arbeite im Großraumbüro.“
- „Mein Sony XM4 ist kaputt. Was ist aktuell besser, der XM5 oder die Bose 700?“
Drei Prompts, eine Absicht. Aber die semantische Ähnlichkeit zwischen diesen Prompts liegt bei gerade einmal 0,081 auf einer Skala von 0 bis 1. Für die KI sind das drei grundverschiedene Anfragen, die zu drei grundverschiedenen Antworten führen. Der Flugzeug-Prompt gewichtet Komfort und Akkulaufzeit, der Großraumbüro-Prompt priorisiert ANC-Qualität im Alltag, der dritte ist ein direkter Produktvergleich.
Für das Tracking bedeutet das: Selbst wenn du hundertmal den Prompt „beste noise cancelling Kopfhörer“ testest und deine Marke in 70 % der Fälle auftaucht, sagt das wenig darüber aus, ob du auch bei den realen Prompts der Nutzer erscheinst. Denn echte Nutzer formulieren eben nicht generisch. Sie geben Budgets mit, beschreiben ihre Situation, nennen Konkurrenzprodukte. Jeder Prompt erzeugt einen eigenen Kontextraum mit eigenen Wahrscheinlichkeiten.
Die Inkonsistenz, die wir bei identischen Prompts gesehen haben, verschärft sich durch diese Hyperkontextualisierung noch einmal drastisch. Wer Sichtbarkeit messen will, muss also nicht nur viele Durchläufe machen, sondern auch mit einem breiten, realistischen Prompt-Set arbeiten. Fünf generische Testprompts reichen nicht.
Die Lösung: Visibility Percentage statt Rankingposition
Wenn einzelne Rankings nicht funktionieren und generische Prompts die Realität nicht abbilden: Was funktioniert dann? Die Antwort liegt in der Statistik. Genauer gesagt: im Gesetz der Großen Zahl.
Statt zu fragen „Auf welchem Platz stehen wir in ChatGPT für Autokredit?“ lautet die richtige Frage: „In wie viel Prozent aller relevanten Prompt-Durchläufe zum Thema Autofinanzierung wird unsere Marke genannt?“ Der Unterschied klingt subtil, verändert aber die gesamte Messlogik.
Nehmen wir an, du schickst fünf Prompts zum Thema Autokredit an ChatGPT. Dreimal taucht deine Marke auf, zweimal nicht. Ergebnis: 60 % Sichtbarkeit. Klingt nach einer Aussage, ist aber statistisch wertlos. Denn bei nur fünf Durchläufen schwankt das Ergebnis so stark, dass der nächste Testlauf genauso gut 20 % oder 100 % ergeben könnte.
Bei hundert Durchläufen mit diversen, realistischen Prompts sieht das anders aus. Wenn deine Marke in 67 von 100 Fällen erscheint, hast du eine Visibility Percentage von 67 %. Dieser Wert ist statistisch belastbar, reproduzierbar und vergleichbar. Du kannst ihn über Zeit tracken und Trends erkennen. Du kannst ihn gegen Wettbewerber benchmarken. Und du kannst messen, ob deine Optimierungsmaßnahmen tatsächlich etwas bewirken.
Die Visibility Percentage misst im Kern etwas, das wir aus dem letzten Abschnitt bereits kennen: wie stark die KI deine Marke mit einem bestimmten Thema assoziiert. Sie macht den abstrakten Kontextraum quantifizierbar. Wer eine hohe Visibility Percentage hat, ist tief im Kontextraum verankert. Wer niedrig liegt, taucht nur sporadisch auf und könnte bei der nächsten Modellversion ganz verschwinden.
Der Haken: Das Ganze ist aufwändig und kostspielig. Ein belastbares Prompt-Set zu erstellen, das reale Nutzerfragen abbildet, hunderte Durchläufe zu fahren und die Ergebnisse statistisch sauber auszuwerten, ist weder schnell noch billig (für den Privatnutzer). Aber es ist die einzige Methode, die tatsächlich misst, was sie zu messen vorgibt.
Das Log-Problem: Wenn Tracking die eigenen Daten sabotiert
An dieser Stelle höre ich oft den Einwand: „Kann ich nicht einfach meine Server-Logs auswerten? Wenn ein KI-Bot meine Seite besucht, wurde sie als Quelle für eine Antwort genutzt. Dann muss ich doch nur zählen, wie oft GPTBot oder der Anthropic-Crawler vorbeikommen.“
Grundsätzlich stimmt die Logik. Server-Log-Analyse ist sogar eine der besten Methoden, um reale KI-Sichtbarkeit zu messen. Aber sie funktioniert nur unter einer Bedingung: Die Daten dürfen nicht kontaminiert sein. Und genau hier liegt das Problem, das erstaunlich wenige auf dem Schirm haben.
Stell dir folgenden Kreislauf vor. Du nutzt ein GEO-Tracking-Tool, das täglich 1.000 Prompts an ChatGPT, Claude und Perplexity schickt, um deine Sichtbarkeit zu messen. Bei einem Teil dieser Prompts greift die KI über RAG auf externe Quellen zurück, also auf die Google-Suche. Deine Seite rankt dort, der KI-Bot besucht sie. In deinen Server-Logs erscheint ein GPTBot-Zugriff. Dein Marketing-Team sieht den Traffic und feiert: „Wir werden immer häufiger von der KI gecrawlt, unsere Sichtbarkeit steigt!“ In Wahrheit misst es die Zugriffe, die das eigene Tracking-Tool ausgelöst hat.
Das ist kein theoretisches Szenario. Es passiert täglich bei Unternehmen, die gleichzeitig KI-Sichtbarkeit tracken und Server-Logs als Erfolgskennzahl verwenden. Das Tool erzeugt Nachfrage, die Logs messen diese künstliche Nachfrage, und am Ende steht eine selbsterfüllende Prophezeiung in der Quartalsauswertung. Die einzige verlässliche Datenquelle, die du hast, nämlich das tatsächliche Crawl-Verhalten der KI-Bots bei echten Nutzeranfragen, wird durch das tägliche Tracking-Rauschen überlagert und letztlich unbrauchbar.
Je häufiger das Tool Prompts sendet, desto stärker die Verzerrung. Und je mehr Unternehmen solche Tools einsetzen, desto verrauschter wird das gesamte Signal im Web.
Was tatsächlich funktioniert: Zwei Säulen der GEO-Erfolgsmessung
Trotz aller Einschränkungen ist GEO-Performance messbar. Aber eben nicht mit der Ranking-Logik, die wir aus der klassischen Suche kennen, sondern mit einem anderen Methodenset. In der Praxis haben sich zwei Säulen bewährt, die sich ergänzen, aber bewusst voneinander getrennt bleiben sollten.
Säule 1: Fortlaufende Log-Analyse. Deine Server-Logs zeigen dir, welche KI-Bots deine Seite wie häufig besuchen und welche Seiten sie abrufen. GPTBot, Bingbot, der Anthropic-Crawler und andere lassen sich eindeutig identifizieren. Daraus kannst du ableiten, welche Inhalte von KI-Systemen als Quelle herangezogen werden und wie sich die Crawl-Frequenz über Zeit entwickelt. Wichtig dabei: Unterscheide zwischen Crawls, die der Antwortgenerierung dienen, und solchen, die dem KI-Training zuzuordnen sind. Und halte dein GEO-Tracking-Tool von dieser Datenquelle fern, sonst landest du im Kreislauf aus dem vorherigen Abschnitt.
Säule 2: Periodisches Benchmarking über Visibility Percentage. Nicht täglich, sondern wöchentlich oder monatlich. Mit einem breiten, realistischen Prompt-Set, das echte Nutzerformulierungen abbildet. Nennungsfrequenz pro Thema messen, Trends über Zeit vergleichen, gegen Wettbewerber benchmarken. Das liefert belastbare Werte ohne die eigenen Logs zu kontaminieren.
Die Betonung liegt auf „periodisch“. Wer täglich trackt, sabotiert seine Daten. Wer gar nicht trackt, navigiert blind. Der Mittelweg ist ein strategisches, zeitlich gesteuertes Monitoring, das bewusst zwischen Messintervallen pausiert.
Ich fasse zusammen: KI-Antworten sind probabilistisch. Einzelne Rankings zu tracken ist sinnlos. Visibility Percentage über breite Prompt-Sets funktioniert, ist aber aufwändig. Server-Logs sind eine wertvolle Datenquelle, solange du sie nicht durch dein eigenes Tracking verunreinigst. Und wer dir ein Tool verkaufen will, das „dein ChatGPT-Ranking“ auf zwei Nachkommastellen genau anzeigt, verkauft dir eine Illusion.
So viel zur Frage, wie sich Sichtbarkeit in der KI-Suche messen lässt. Bleibt die wichtigste Frage überhaupt: Wie verbessere ich diese Sichtbarkeit konkret? Was muss auf meiner Seite passieren, damit KI-Systeme meine Inhalte zitieren? Und was muss abseits meiner Seite passieren, damit meine Marke empfohlen wird? Darum geht es im letzten Artikel meiner Reihe zur KI-Suche.