Topical Maps: Warum die meisten eigentlich gar keine sind – und wie es richtig geht

Es gibt wenige Begriffe in der SEO-Branche, die so inflationär verwendet und gleichzeitig so gründlich missverstanden werden wie „Topical Map“. Öffne ein beliebiges SEO-Tool, lies irgendeinen Blogartikel zum Thema Content-Strategie, und du wirst sie finden: bunte Mindmaps mit dem Hauptkeyword in der Mitte und Unterthemen drumherum. „Topical Map“, steht drüber. Fertig.
Das Problem: Was da entsteht, ist in den allermeisten Fällen keine Topical Map. Es ist eine Concept Map – ein enzyklopädisches Abbild eines Themas, zusammengeklickt aus Wikipedia-Kategorien, Keyword-Tools und gesundem Menschenverstand. Und genau hier liegt der Fehler, den fast die gesamte Branche macht.
Der Unterschied ist nicht kosmetisch denn vielmehr fundamental. Und er entscheidet darüber, ob dein Content-Netzwerk bei Google systematisch Relevanz aufbaut, oder ob du Hunderte Artikel veröffentlichst, die sich gegenseitig die Sichtbarkeit klauen.
In diesem Artikel erkläre ich, was eine echte Topical Map von einer Concept Map unterscheidet, warum Query-Netzwerke und Nutzerverhalten die Grundlage jeder seriösen Content-Architektur sein müssen, und wie Konzepte wie Entity-Attribute, Source Context und Contextual Vectors zusammenwirken, um eine Website semantisch zu positionieren. Die theoretische Grundlage dafür liefert unter anderem das Framework von Koray Tuğberk – einem der wenigen SEOs, die das Thema Topical Map wirklich von den Grundlagen der Suchmaschinen-Architektur her denken.
Was die meisten unter „Topical Map“ verstehen
Lass mich beschreiben, wie der typische Prozess aussieht, den SEO-Agenturen als „Topical Map erstellen“ verkaufen.
Du nimmst dein Hauptthema – sagen wir „Kreditkarte“. Du wirfst es in ein Keyword-Tool und bekommst Cluster zurück: „Kreditkarte beantragen“, „Kreditkarte ohne Schufa“, „Kreditkarte Vergleich“, „beste Kreditkarte für Reisen“. Du gruppierst die Keywords in Unterthemen und ordnest sie hierarchisch an. Daraus leitest du Artikel ab – einen pro Cluster. Du verlinkst alles auf einen Pillar-Artikel und nennst das Ergebnis „topische Autorität“.
Das klingt logisch. Es sieht professionell aus. Und es ist trotzdem falsch.
Warum? Weil du mit diesem Ansatz nur nachbaust, was in einer Enzyklopädie stehen würde. Du definierst „Kreditkarte“ und zählst ihre Eigenschaften auf – genau so, wie es ein Lexikoneintrag tun würde. Die Frage „Was gehört alles zum Thema Kreditkarte?“ beantwortest du nach enzyklopädischer Logik: Was ist eine Kreditkarte? Welche Typen gibt es? Was kostet sie? Wie beantrage ich sie? Das ist eine Concept Map. Ein Wissensbaum, der alles abbildet, was man über einen Begriff wissen kann.
Das Ergebnis sieht auf den ersten Blick vollständig aus. Aber es fehlt etwas Entscheidendes: der Bezug zu dem, was Nutzer tatsächlich suchen – und in welcher Reihenfolge, in welcher Kombination und aus welchem Kontext heraus. Denn eine Suchmaschine organisiert Wissen nicht wie ein Lexikon. Sie organisiert es wie ein Netzwerk aus Suchanfragen.
Und genau das ist der Unterschied. Eine Concept Map fragt: Was gehört zu diesem Thema? Eine Topical Map fragt: Welche Suchanfragen bilden zusammen ein kohärentes Themengebiet – und wie hängen sie untereinander zusammen? Das klingt ähnlich, führt aber zu völlig unterschiedlichen Content-Architekturen.
Semantische Nähe kommt nicht aus dem Wörterbuch
Um zu verstehen, warum die Concept-Map-Logik scheitert, musst du eine Ebene tiefer gehen und dir eine simple Frage stellen: Woher „weiß“ eine Suchmaschine eigentlich, welche Themen zusammengehören?
Die Antwort, die die meisten SEOs geben würden: Weil die Themen inhaltlich verwandt sind. Kreditkarte und Schufa gehören zusammen, weil die Schufa bei der Kreditkartenbeantragung relevant ist. Deutschland und Frankreich gehören zusammen, weil sie Nachbarländer sind. Klingt plausibel. Ist aber nur die halbe Wahrheit – und in vielen Fällen sogar irreführend.
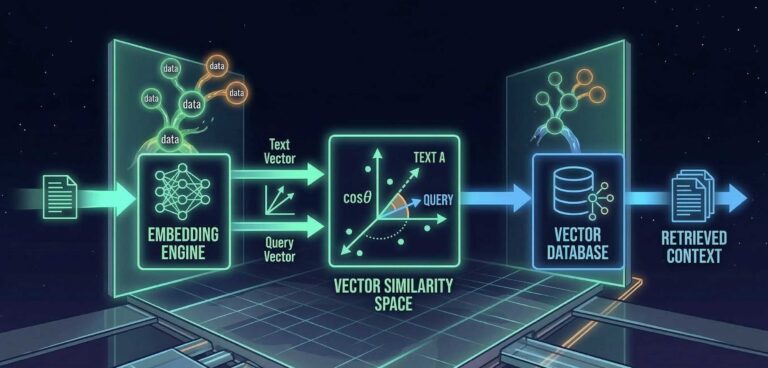
Suchmaschinen lernen thematische Zusammenhänge primär aus Nutzerverhalten. Aus Suchsessions, Query-Pfaden und korrelativen Suchanfragen. Wenn Tausende Nutzer nach „Kreditkarte beantragen“ suchen und in derselben Session anschließend „Schufa Score verbessern“ eingeben, dann lernt die Suchmaschine: Diese beiden Themen hängen zusammen. Nicht weil es im Duden steht, sondern weil echte Menschen sie verknüpfen.
Das ist dasselbe Prinzip, das ich in meinem Artikel über die KI-Suche erklärt habe: Query-Semantik ist keine Wörterbuch-Semantik. Die Bedeutung einer Suchanfrage wird nicht durch Definitionen festgelegt, sondern durch das kollektive Verhalten der Nutzer. Und das hat Konsequenzen für die gesamte Architektur einer Topical Map.
Ein Beispiel macht das sofort greifbar. Stell dir vor, du betreibst eine Website zum Thema „Visum für Deutschland“. Deine zentrale Entität ist Deutschland. Jetzt die Frage: Welches andere Land ist semantisch am nächsten zu Deutschland?
Die meisten Menschen antworten: Frankreich. Oder Österreich. Nachbarländer. Geografisch nahe, kulturell verwandt. Enzyklopädisch betrachtet absolut richtig.
Aber wenn du dir die tatsächlichen Query-Netzwerke anschaust – also die Suchanfragen, die Nutzer in denselben Sessions stellen –, ergibt sich ein völlig anderes Bild. Die Länder, die im Kontext „Visum für Deutschland“ semantisch am nächsten liegen, sind häufig Bulgarien, die Türkei oder Litauen. Nicht weil sie geografisch nah liegen – sondern weil die Nutzer, die nach einem Visum für Deutschland suchen, häufig auch nach Visa für genau diese Länder suchen. Ein typischer Grund: Erasmus-Programme. Studenten aus diesen Regionen suchen nach Bildungsvisa, und ihre Suchsessions verbinden diese Länder miteinander. Das widerspricht fundamental dem, was die meisten SEOs unter thematischer Nähe verstehen.
Und das ist kein Randfall. Das ist die Regel. Semantische Distanz wird nicht durch Wörterbücher definiert, sondern durch Nutzerverhalten. Und wenn du deine Topical Map auf Wörterbuch-Logik aufbaust, baust du sie auf dem falschen Fundament. Du ordnest deine Inhalte so an, wie es ein Lexikon tun würde – und wunderst dich, warum die Suchmaschine deine thematische Autorität nicht erkennt. Wer mehr über dieses Beispiel erfahren möchte, der sollte Korays Kurs absolvieren.
Es geht aber sogar noch weiter. Semantische Distanz ist nicht statisch. Nach jedem Google Core Update können sich die Abstände zwischen Themen verschieben, weil neue Nutzerdaten einfließen und Suchmuster sich verändern. Was heute thematisch nah beieinanderliegt, kann morgen weiter entfernt sein – und umgekehrt. Wer das versteht, versteht auch, warum Content-Konfiguration kein einmaliger Vorgang ist, sondern ein fortlaufender Prozess.
Die Bausteine einer echten Topical Map
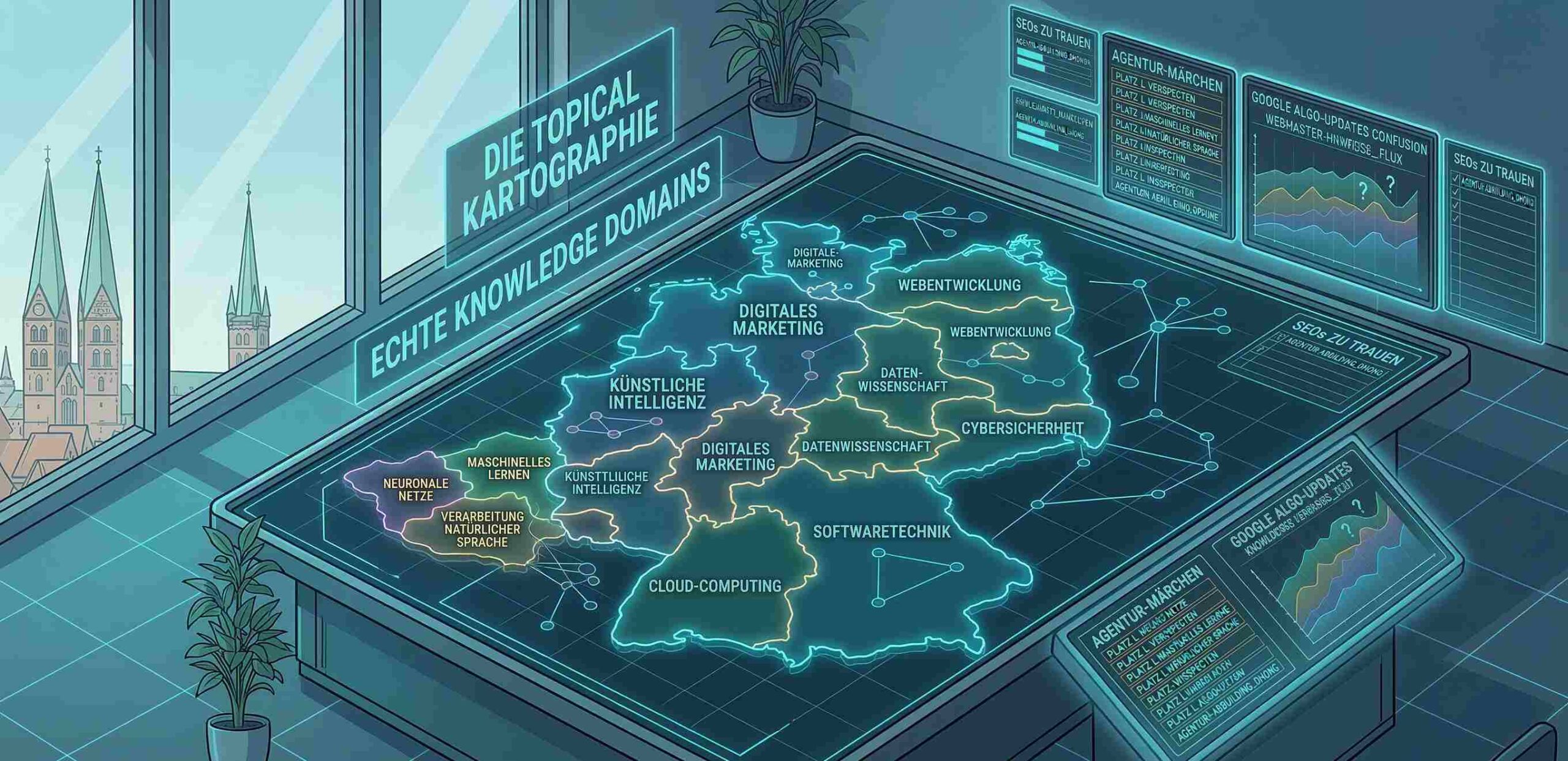
Wenn du eine echte Topical Map erstellen willst, startest du nicht mit Keywords. Du startest mit einer Frage, die überraschend wenige SEOs stellen: Welcher Entity-Typ dominiert mein Themengebiet?
Jedes Query-Netzwerk wird von einem bestimmten Typ von Entität strukturiert. Im Visa-Beispiel von eben sind es Länder. In einem Rezepte-Blog wären es Gerichte oder Zutaten. In einem Finanzportal wären es Finanzprodukte. In einem Reiseblog wären es Städte. Dieser dominante Entity-Typ ist das Grundgerüst deiner gesamten Content-Architektur – und trotzdem wird er in den meisten „Topical Map“-Anleitungen nicht einmal erwähnt.
Dein erster Schritt ist, diesen Typ zu identifizieren. Der zweite: Alle Instanzen dieses Typs auflisten. Alle Länder, alle Gerichte, alle Finanzprodukte. Der dritte: Diese Instanzen nach semantischer Nähe gruppieren – nicht nach enzyklopädischer Logik, sondern nach dem tatsächlichen Query-Verhalten der Nutzer. So entstehen deine thematischen Cluster. Nicht aus Keyword-Tools, sondern aus der Struktur der Suchanfragen selbst.
Attribute filtern: Nicht alles gehört in deine Topical Map
Sobald du deine Entitäten identifiziert hast, geht es eine Ebene tiefer: an die Attribute. Jede Entität hat Dutzende davon. Deutschland hat eine Bevölkerung, eine Flagge, eine Fußball-Liga, eine Hauptstadt, ein politisches System, eine Küche. Die Frage ist nicht, welche Attribute existieren – sondern welche davon für deine Topical Map relevant sind.
Und hier machen die meisten den zweiten großen Fehler: Sie nehmen alles mit. „Deutschland“ als zentrales Entity, also müssen wir auch über die Bundesliga schreiben, weil das ja zu Deutschland gehört. Nein. Nicht wenn du eine Visa-Website betreibst.
Die Filtration funktioniert über drei Kriterien.
Attribute Prominence fragt: Ist dieses Attribut so fundamental, dass man die Entität ohne es nicht mehr definieren kann? Die Bevölkerung eines Landes – ja. Ohne Bevölkerung kein Land. Die Bundesliga – nein. Ohne Bundesliga ist Deutschland immer noch Deutschland. Prominente Attribute definieren die Entität selbst. Wenn du sie weglässt, verliert die Entität ihren Typ.
Attribute Popularity fragt: Wird nach diesem Attribut in Verbindung mit der Entität viel gesucht? Die Bundesliga in Verbindung mit Deutschland hat hohes Suchvolumen. Aber Suchvolumen allein ist kein ausreichendes Kriterium – sonst würdest du auf deiner Visa-Website über Fußball schreiben, weil es populär ist.
Attribute Relevance fragt: Passt dieses Attribut zu deinem Source Context? Und das ist der entscheidende Filter.
Source Context: Warum nicht jedes Thema dein Thema ist
Dein Source Context ist die Schnittmenge aus dem, was du anbietest, wer du bist und welche thematische Identität deine Website hat. Bei einer Visa-Beratung ist der Source Context: Einreise, Aufenthalt, Bildung, Arbeit in einem bestimmten Land. Die Bundesliga ist populär, aber irrelevant für diesen Kontext. Die Bevölkerung hingegen ist sowohl prominent als auch relevant, weil sie sich kontextuell mit Themen wie Lebenshaltung, Integration und Einwanderung verbinden lässt.
Erst wenn ein Attribut in mindestens zwei dieser drei Dimensionen besteht – und immer mit Relevance als hartem Filter –, verdient es einen Platz in deiner Topical Map. Alles andere ist Ballast. Und Ballast ist in einer semantischen Content-Architektur nicht neutral – er verwässert aktiv die Relevanz deiner gesamten Website.
Dieses Prinzip erklärt auch, warum manche Websites mit 30 Artikeln mehr thematische Autorität aufbauen als andere mit 300. Es geht nicht um Masse. Es geht darum, ob jeder einzelne Inhalt die kontextuelle Relevanz der gesamten Website stärkt – oder ob er sie durch thematische Streuung schwächt.
Central Search Intent: Der rote Faden deiner gesamten Website
Ein letzter Baustein, den die meisten Topical-Map-Ansätze komplett ignorieren: der Central Search Intent. Das ist nicht die Suchintention eines einzelnen Keywords. Es ist die übergeordnete Absicht, die alle Inhalte deiner Website verbindet.
Zurück zum Visa-Beispiel. Was ist der Central Search Intent? Die meisten würden sagen: „Ein Visum beantragen.“ Aber das ist zu eng gedacht. Der eigentliche Intent ist breiter: Deutschland kennenlernen und nach Deutschland gehen – mit einem bestimmten Visum als konkretem Schritt darin. „Kennenlernen“ und „[nach Deutschland] gehen“ sind die beiden zentralen Prädikate, die sich durch die gesamte Website ziehen müssen.
Warum ist das wichtig? Weil der Central Search Intent bestimmt, welche Inhalte zum Kern deiner Topical Map gehören und welche zur Peripherie. Die Visa-Artikel – das ist der Kern. Dort verdienst du Geld, dort liegt dein Source Context. Aber die Artikel über Kultur, Geografie, Sprache, Lebenshaltung? Die gehören zur äußeren Schicht der Topical Map. Sie existieren nicht, um direkt zu konvertieren, sondern um die thematische Relevanz deiner Website zum zentralen Entity – Deutschland – zu erhöhen. Sie beweisen der Suchmaschine: Diese Website versteht Deutschland umfassend. Also kann sie auch beim Thema Visum vertrauenswürdig sein.
Diese Unterscheidung zwischen Kern und Peripherie ist einer der Gründe, warum echte Topical Maps funktionieren und Concept Maps nicht. Die Concept Map behandelt alles gleich. Die Topical Map priorisiert – auf Basis von Source Context, Entity-Attributen und Nutzerverhalten.
Warum nichts zufällig ist: Contextual Vectors und die Architektur eines Artikels
Bis hierhin haben wir über die Struktur gesprochen – welche Entitäten, welche Attribute, welche Cluster. Aber eine Topical Map ist nicht nur ein Organigramm. Sie bestimmt auch, wie jeder einzelne Artikel aufgebaut sein muss. Und hier wird es für die meisten SEOs richtig unbequem, weil es bedeutet: Nichts in einem Artikel darf zufällig sein. Nicht die Reihenfolge der Überschriften, nicht die Wortwahl in der Einleitung, nicht die Platzierung einer internen Verlinkung.
Das Konzept dahinter heißt Contextual Vector – und es ist im Grunde simpel: Jeder Artikel erzählt einen kontextuellen Faden, der von der ersten Überschrift bis zum letzten Absatz als gerade Linie verläuft. Kein Abschweifer, kein Themenwechsel, kein Abschnitt, der nicht zum Rest passt. Wenn du dir den Kontextfluss eines gut gebauten Artikels vorstellst, ist er eine Gerade. Bei den meisten Artikeln – egal ob von Menschen oder KI geschrieben – sieht er eher aus wie ein Zickzack-Kurs: Thema hier, anderes Thema da, dann ein Absatz, der eigentlich in einen anderen Artikel gehört.
Das ist keine stilistische Präferenz, denn vielmehr ein technisches Problem. Suchmaschinen bewerten die kontextuelle Kohärenz eines Dokuments. Wenn dein Artikel über Studentenvisa für Deutschland plötzlich einen Absatz über das deutsche Autobahnnetz enthält, unterbricht das den Contextual Vector. Die Suchmaschine muss entscheiden: Worum geht es hier eigentlich? Und je öfter sie diese Frage stellen muss, desto weniger vertraut sie deiner Antwort auf die ursprüngliche Suchanfrage.
Das Root-Dokument: Dein wichtigster Artikel
In einer echten Topical Map gibt es ein Dokument, das über allem steht: das Root-Dokument. Es ist der Artikel, der direkt auf deine zentrale Entität einzahlt und von dem aus alle anderen Artikel erreichbar sind. In unserem Visa-Beispiel wäre das so etwas wie „Was du wissen musst, bevor du nach Deutschland gehst“ – ein Artikel, der die zentralen Prädikate „[nach Deutschland] gehen“ und „Kennenlernen“ direkt in der H1 trägt.
Warum ist dieses Dokument so wichtig? Weil es an der Wurzel deines gesamten Informationsbaums steht. Jedes andere Dokument in deiner Topical Map wird direkt oder indirekt von diesem Root-Dokument aus verlinkt. Wenn das Root-Dokument schlecht ist – thematisch unscharf, kontextuell inkohärent, schlecht strukturiert –, dann zieht es die Relevanz aller nachgeordneten Dokumente mit nach unten. Die Suchmaschine denkt: Wenn schon der Hauptartikel zur zentralen Entität schwach ist, warum sollte ich den Unterartikeln vertrauen?
Das ist der Grund, warum in einer professionellen semantischen Content-Strategie das Root-Dokument zuerst geschrieben, am sorgfältigsten gepflegt und regelmäßig rekonfiguriert wird. Es ist nicht einfach ein weiterer Blogartikel. Es ist das Fundament.
Heading-Hierarchie ist nicht Dekoration
In den meisten SEO-Ratgebern liest du: „Nutze H2 für Hauptabschnitte und H3 für Unterabschnitte.“ Das ist technisch korrekt und inhaltlich nutzlos. Denn es beantwortet nicht die eigentliche Frage: In welcher Reihenfolge und mit welcher kontextuellen Verbindung?
In einem semantisch aufgebauten Artikel folgt jede Überschrift aus der vorherigen. Die letzte Zeile eines Abschnitts enthält einen kontextuellen Hinweis auf das, was im nächsten Abschnitt kommt. Nicht als plumpe Überleitung im Stil von „Im nächsten Abschnitt geht es um …“, sondern als inhaltliche Brücke: Ein Begriff, ein Konzept, ein Aspekt wird am Ende von Abschnitt A eingeführt und in Abschnitt B vertieft. So entsteht ein kontextueller Fluss, der für die Suchmaschine genauso lesbar ist wie für einen Menschen.
Gleichzeitig bestimmt die Heading-Hierarchie, wo interne Links platziert werden – und das ist alles andere als beliebig. Wenn du in einer H3 einen Begriff verwendest, der in einem anderen Artikel als H1 fungiert, dann ist das der natürliche Ort für eine interne Verlinkung. Aber bevor du diesen Link setzt, muss der Begriff im Fließtext bereits kontextuell eingebettet sein. Das nennt man Internal Link Justification: Du verlinkst nicht einfach ein Keyword, sondern du baust im umgebenden Text die Relevanzbrücke, die den Link rechtfertigt.
Das klingt nach viel Aufwand. Ist es auch. Aber es ist der Unterschied zwischen einer Content-Architektur, in der jeder Artikel den nächsten stärkt – und einer, in der Hunderte Artikel isoliert nebeneinander existieren und sich im schlimmsten Fall gegenseitig kannibalisieren.
Warum KI-generierte Inhalte hier versagen
An dieser Stelle wird auch klar, warum rein KI-generierte Artikel in einer echten Topical Map fast nie funktionieren. Nicht weil die Sprache schlecht wäre – die ist mittlerweile oft passabel. Sondern weil ein Large Language Model den Contextual Vector nicht halten kann, wenn es den Gesamtkontext der Topical Map nicht kennt. Es weiß nicht, welche Begriffe in welchem anderen Artikel als H1 stehen. Es weiß nicht, welche internen Links gerechtfertigt werden müssen. Es weiß nicht, welche Attribute prominent, populär und relevant sind. Es produziert Text, der für sich genommen in Ordnung klingt – aber der nicht in ein semantisches Netzwerk eingebettet ist.
Und genau das sieht die Suchmaschine. Nicht weil sie erkennt, dass ein Text von einer KI geschrieben wurde. Sondern weil der Text keinen kohärenten Contextual Vector hat und nicht in eine durchdachte Informationsarchitektur eingebunden ist. Der Zickzack-Kurs ist das Problem – nicht die Herkunft des Textes.
Topical Authority verdient man sich nicht mit Masse
Fassen wir zusammen, was eine echte Topical Map von dem unterscheidet, was die Branche meistens darunter versteht.
Eine Concept Map organisiert Wissen wie ein Lexikon: hierarchisch, vollständig, enzyklopädisch. Sie beantwortet die Frage „Was gehört zu diesem Thema?“ – und leitet daraus Artikel ab. Das Ergebnis sind Content-Pläne mit 50, 100, 200 Artikeln, die thematisch irgendwie zusammenhängen, aber kein semantisches Netzwerk bilden.
Eine Topical Map organisiert Wissen so, wie eine Suchmaschine es tut: auf Basis von Query-Netzwerken, Nutzerverhalten und semantischer Distanz. Sie identifiziert den dominanten Entity-Typ, filtert Attribute nach Prominence, Popularity und Relevance, definiert einen Source Context und einen Central Search Intent – und baut daraus eine Content-Architektur, in der jeder Artikel die Relevanz jedes anderen Artikels stärkt.
Der Unterschied ist nicht akademisch. Er entscheidet darüber, ob deine Website nach bereits wenigen Artikeln als thematische Autorität wahrgenommen wird – oder ob sie nach Hunderten Artikeln immer noch auf Seite drei steht, weil die Suchmaschine nicht versteht, wofür du eigentlich stehst und was dein Thema ist.
Und dieser Unterschied erklärt ein Phänomen, das viele SEOs frustriert: Warum kleine, fokussierte Websites manchmal deutlich besser ranken als große Portale mit zigfach mehr Content. Die Antwort ist fast immer dieselbe. Die kleine Website hat ein kohärentes semantisches Netzwerk. Die große hat eine Sammlung von Artikeln.
Wer ernsthaft an Topical Authority arbeiten will, muss bereit sein, drei Dinge zu akzeptieren:
Erstens: Nicht jedes Thema, das zu deiner Branche gehört, gehört auch auf deine Website. Dein Source Context ist dein Filter. Was nicht relevant ist, wird nicht geschrieben – egal wie hoch das Suchvolumen ist.
Zweitens: Die Reihenfolge und Struktur deiner Inhalte ist genauso wichtig wie die Inhalte selbst. Ein Artikel, der kontextuell nicht an die restliche Architektur angebunden ist, schadet der SEO-Performance insgesamt.
Drittens: Content-Konfiguration ist kein einmaliger Vorgang. Semantische Distanzen verschieben sich, Nutzerverhalten ändert sich, neue Query-Netzwerke entstehen. Wer seine Topical Map einmal erstellt und dann nie wieder anfasst, hat den Kern des Konzepts nicht verstanden.
Topical Authority ist kein Abzeichen, das man sich verdient, indem man genug Artikel veröffentlicht. Vielmehr ist sie das Ergebnis einer Architektur, in der Entity-Typen, Attribute, kontextuelle Vektoren und interne Verlinkungen ein kohärentes Ganzes bilden. Wer das ignoriert und stattdessen Keyword-Cluster aus einem Tool in einen Redaktionsplan kippt, betreibt Content-Produktion und gewiss keine Suchmaschinenoptimierung.