Wie ich mir eine eigene SEO-Wissensbibliothek gebaut habe — als Nicht-Programmierer

Wer sich beruflich mit (semantischer) SEO beschäftigt, sammelt über die Jahre einen Wissenskorpus, der irgendwann unübersichtlich wird. Bei mir waren es hunderte Quellen: Fachartikel, YouTube-Transkripte, Google-Patente, Research Papers, Konferenzvorträge, PDFs. Wissen, das ich gelesen, verstanden und in meiner täglichen Arbeit angewendet hatte — aber das verstreut auf Festplatten, in Browser-Lesezeichen und in meinem Kopf lag.
Ich wollte dieses Wissen durchsuchbar machen. Nicht über Strg+F in einzelnen Dokumenten, sondern über alle Quellen hinweg, semantisch, also nach Bedeutung, nicht nach exakten Wörtern. Ich wollte einer KI eine Fachfrage stellen können und dafür genau die Stellen aus meinen Quellen zurückbekommen, die diese Frage tatsächlich beantworten. Nur das, was in den Quellen steht.
Das klingt nach einem einfachen Problem. Ist es nicht.
Wer schon einmal versucht hat, einem großen Sprachmodell hunderte Seiten Fachliteratur mitzugeben und dann gezielte Fragen zu stellen, weiß: Die Modelle bleiben nicht bei den Quellen. Sie erfinden Zusammenhänge, die plausibel klingen, aber so nie formuliert wurden. Sie ergänzen Annahmen, die nirgends stehen. Und je mehr Material man mitgibt, desto unkontrollierbarer wird das Ergebnis — weil das Modell nicht weiß, welche Stellen gerade relevant sind und welche nicht.
Bestehende Lösungen halfen nicht weiter. Claude Projects, ChatGPT, NotebookLM — überall dasselbe Muster: Blackbox-Retrieval, begrenzte Kontextfenster, keine Transparenz darüber, welche Stellen das Modell gerade „sieht“. Manuelles Copy-Paste war bei über 300 Quellen keine Option.
Also habe ich mir eine eigene Lösung gebaut. Eine lokale Wissensbibliothek, die mein gesamtes Quellenmaterial semantisch durchsuchbar macht und direkt an Claude angebunden ist — als Recherche-Instrument, nicht als Textmaschine. Und ich bin kein Programmierer. Also kannst du das auch — vorausgesetzt, du bist bereit, dich durch einige Fehler zu arbeiten. Also, los geht es.
Was ich eigentlich wollte: gesammeltes SEO-Wissen unmittelbar zugänglich machen
Mein Ausgangspunkt war ein konkreter Anwendungsfall. Ich schreibe Fachartikel über SEO, meist auf Basis von Primärquellen. Patente, Studien, Originalpublikationen von Leuten, die das Fachgebiet tatsächlich vorangebracht haben. Wer meine bisherigen Artikel kennt, weiß: Ich zitiere nicht Blogposts, sondern die Quellen, auf die sich Blogbeiträge beziehen. In der Regel zumindest.
Wenn ich also für einen Artikel recherchiere, brauche ich Zugriff auf sehr spezifische Stellen in diesem Korpus. Nicht das gesamte Dokument, sondern den einen Absatz, in dem ein bestimmtes Konzept erklärt wird. Oder die drei Stellen, an denen verschiedene Autoren dasselbe Phänomen aus unterschiedlichen Perspektiven beschreiben. Das ist Recherchearbeit, die ich bisher im Kopf gemacht habe: Ich wusste ungefähr, wer was wo geschrieben hatte, und habe manuell nachgeschlagen.
Bei 50 Quellen funktioniert das. Bei 300 nicht mehr.
Mein erster Gedanke war: ein eigenes KI-Modell trainieren. Ein Sprachmodell, das ausschließlich mein Quellenmaterial kennt und daraus antwortet. Im Gespräch mit Claude stellte sich schnell heraus, dass das der falsche Ansatz ist. Kleinere Modelle halluzinieren nicht weniger als große — sie halluzinieren mehr, weil ihnen die sprachliche Kompetenz fehlt, Unsicherheit zu erkennen. Und ein Modell lokal zu trainieren, ohne GPU, ist schlicht nicht praktikabel.
Was ich tatsächlich brauchte, war kein eigenes Modell, sondern ein System, das einem großen, leistungsfähigen Modell wie Claude gezielt die richtigen Quellenstellen liefert, statt ihm alles auf einmal vor die Füße zu kippen.
In der Fachsprache heißt dieses Prinzip Retrieval Augmented Generation — kurz RAG. Die Idee dahinter ist jedem, der sich mit KI-Suche beschäftigt, nicht fremd: Statt einem Modell alles beizubringen, gibt man ihm im Moment der Anfrage nur die relevanten Informationen. Dasselbe Prinzip, das auch hinter der Suche in KI-Chatbots steckt. Nur eben angewandt auf meinen persönlichen Wissenskorpus.
Was das System tut — ohne fancy Coding-Wording
Das System besteht im Kern aus drei Dingen: einer Suchmaschine, einem Wiki und einer Anbindung an Claude. Kein einzelnes davon ist besonders spektakulär. Zusammen ergeben sie ein leistungsstarkes Recherche-Instrument.
Erstens: Die Suche
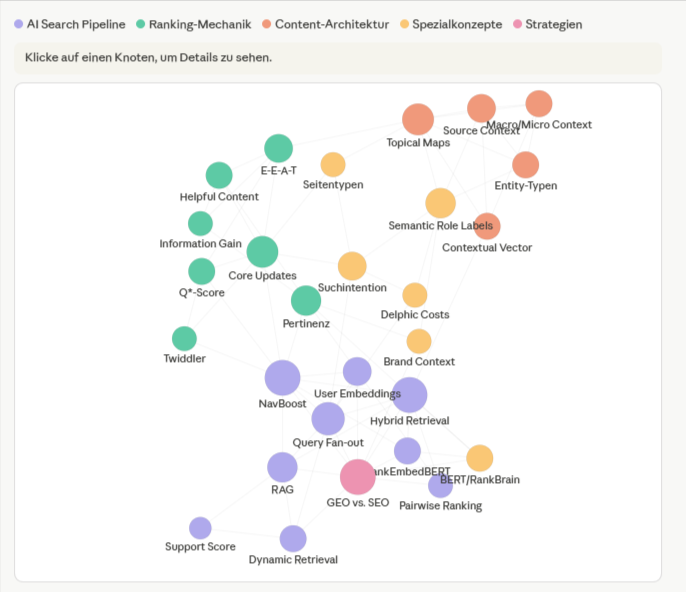
Wenn ich dem System eine Frage stelle — etwa „Wie beschreibt Quelle X den Zusammenhang zwischen Entitäten und Ranking?“ — passiert Folgendes: Zwei Suchwege laufen parallel. Der eine sucht nach Bedeutung. Er versteht, dass „Entitäten und Ranking“ inhaltlich verwandt ist mit „Entity-based indexing“, auch wenn diese Wörter in der Anfrage nicht exakt so vorkommen. Das ist Vektorsuche — dasselbe Prinzip, das auch hinter der semantischen Suche bei Google steckt. Texte werden in mathematische Repräsentationen umgewandelt, sogenannte Embeddings, und nach inhaltlicher Nähe verglichen.
Der andere Suchweg ist simpler: Er findet exakte Begriffe. Wenn ich nach „E-E-A-T“ suche, will ich Stellen, in denen buchstäblich „E-E-A-T“ steht — nicht Stellen, die thematisch in die Nähe kommen. Das ist klassische Begriffssuche, im Prinzip ein intelligenteres Strg+F über alle 300 Quellen.
Beide Suchwege liefern Kandidaten. Danach bewertet ein dritter Schritt — ein sogenannter Reranker — alle Kandidaten nochmal nach tatsächlicher Relevanz zur ursprünglichen Frage und sortiert Ballast raus. Was übrig bleibt, sind die Stellen, die wirklich zur Frage passen.
Wer sich mit dem Thema KI-Suche beschäftigt, erkennt das Muster: Das ist Hybrid Retrieval mit Reranking. Dasselbe Architekturprinzip, das auch in modernen Suchsystemen wie Google oder in Retrieval-Augmented-Generation-Pipelines zum Einsatz kommt. Nur eben auf mein persönliches Quellenmaterial angewandt, lokal, auf meinem Rechner.
Warum beide Suchwege nötig sind, zeigt ein einfaches Beispiel: Suche ich nach „Wie bewertet Google die thematische Tiefe einer Website?“, findet die Vektorsuche Stellen über Topical Authority, siteFocusScore und thematische Cluster — auch wenn diese Begriffe in meiner Frage nicht vorkommen. Die Begriffssuche hingegen übersieht all das, weil keines dieser Wörter in der Anfrage steht. Suche ich aber nach einem spezifischen Fachbegriff wie „NavBoost“, ist es umgekehrt: Die Begriffssuche liefert sofort alle Stellen, in denen NavBoost vorkommt. Die Vektorsuche hingegen könnte mir auch Stellen über Klickverhalten oder User Engagement liefern, die thematisch verwandt sind, aber NavBoost nicht erwähnen. Beide Suchwege zusammen decken ab, was einer allein übersieht.
Zweitens: Das Wiki
Die Suche allein löst das Problem ineffizienter Wissensorganisation bei vielen Quellen aber nur halb. Sie findet relevante Stellen — aber bei jeder Anfrage fängt sie von vorn an. Es gibt kein Gedächtnis, keine Akkumulation. Frage ich heute nach Entitäten und morgen nach Topical Authority, weiß das System nicht, dass beides zusammenhängt.
Deshalb gibt es eine zweite Schicht: ein Wiki. Strukturierte Markdown-Artikel, die Claude aus den Rohdaten kompiliert und pflegt. Jede Wiki-Seite fasst ein Konzept zusammen, verweist auf die Originalquellen und verlinkt auf verwandte Seiten. Wenn ich eine neue Quelle importiere, die etwas Relevantes über ein bestehendes Konzept enthält, aktualisiert Claude die entsprechende Wiki-Seite — ergänzt die neue Information, setzt den Querverweis, prüft auf Widersprüche.
Wichtig dabei: Nichts davon passiert automatisch im Hintergrund. Ich stoße den Prozess an, und Claude fragt nach jedem Artikel explizit, ob die neuen Erkenntnisse ins Wiki zurückgeschrieben werden sollen. Ich prüfe die Änderungen, bevor sie übernommen werden. Das Wiki wächst also nicht unkontrolliert, stattdessen wächst es unter Aufsicht.
Der Weg dahin — oder: Warum kein einziger Schritt beim ersten Mal funktionierte
Ich bin kein Programmierer. Ich kann kein Python, kein JavaScript, keine Kommandozeile. Mein Werkzeug ist Sprache — Sprache verstehen, Sprache strukturieren, Sprache so einsetzen, dass Suchmaschinen und Sprachmodelle sie verarbeiten können. Code gehört nicht dazu.
Das System, das ich gerade beschrieben habe, habe ich trotzdem selbst gebaut. Trotz fehlender Programmierkenntnisse, mit Claude als Coding-Asistent. Jeder einzelne Schritt — von der Installation von Python bis zur Anbindung an Claude Desktop — entstand im Dialog: Ich beschreibe, was ich will. Claude liefert den Code. Ich führe ihn aus. Es funktioniert nicht. Ich beschreibe die Fehlermeldung. Claude korrigiert. Ich führe erneut aus. Irgendwann funktioniert es.
Das klingt nach einem sauberen Prozess. War es nicht. Es war ein Stolpern von Problem zu Problem, bei dem jeder gelöste Fehler den nächsten freigelegt hat.
Python installieren: Erster Schritt, erster Fehler. „Add to PATH“ vergessen — eine Checkbox während der Installation, die dafür sorgt, dass Windows Python überhaupt findet. Ohne sie passiert beim Aufruf von Python in der Kommandozeile einfach nichts. Nachträglich über die Umgebungsvariablen gelöst, was ungefähr so intuitiv ist, wie es klingt.
Erste Quelle herunterladen: Falsche URL. Ich hatte die Domain eines Autors verwechselt — ein Fehler, den ich erst bemerkt habe, als das Skript eine völlig andere Website heruntergeladen hatte. Dann die richtige URL, aber die Seite lieferte komprimierte Daten in einem Format, das mein Skript nicht lesen konnte. Neue Bibliothek installiert. Dann konnte das Skript die Seite zwar laden, aber den Artikelinhalt nicht finden — weil die HTML-Struktur der Seite anders aufgebaut war als erwartet. Debug-Skript geschrieben, Seitenstruktur analysiert, Selektoren angepasst.
Für einen einzigen Artikel. Drei Fehler, drei Korrekturen, bevor überhaupt der erste Text in der Datenbank lag.
Beim Batch-Import für viele Quellen wiederholte sich das Muster auf einer anderen Ebene. YouTube-Transkripte herunterladen: Die Programmierschnittstelle hatte sich seit der Version geändert, auf die Claude den Code geschrieben hatte. Funktionsaufruf existierte nicht mehr. Code anpassen. JavaScript-lastige Webseiten, die ihren Inhalt erst nach dem Laden aufbauen: normales Herunterladen lieferte eine leere Seite. Lösung: Einen echten Browser im Hintergrund starten lassen, der die Seite vollständig rendert, bevor der Text extrahiert wird. Das funktionierte — aber nur nach zwei Anläufen, weil der Browser beim ersten Mal nicht korrekt installiert war.
Inkrementelle Indexierung — also die Fähigkeit, nur neue oder geänderte Quellen zu verarbeiten statt jedes Mal alles von vorn — hat drei Anläufe gebraucht. Der erste Ansatz basierte auf dem Änderungsdatum der Dateien. Funktionierte nicht, weil der Import-Prozess die Dateien bei jedem Lauf neu schreibt und damit das Datum aktualisiert. Der zweite Ansatz speicherte den Fortschritt erst am Ende des gesamten Durchlaufs. Bei 300 Dateien dauert ein Durchlauf lang — und wenn er mittendrin abbricht, war alles verloren. Der dritte Ansatz — eine Prüfsumme des Dateiinhalts, gespeichert nach jeder einzelnen Datei — funktionierte.
Das ist ein Muster, das sich durch den gesamten Prozess zieht: Kein einziger Schritt war beim ersten Mal fehlerfrei. Aber jeder Fehler war lösbar, weil ich ihn beschreiben konnte und Claude die Korrektur lieferte. Die Kompetenz, die ich brauchte, war nicht Programmieren. Es war die Fähigkeit, ein Problem präzise genug zu beschreiben, damit ein Sprachmodell die richtige Lösung generieren kann. Das ist — und das sage ich als jemand, der sich beruflich mit der Interaktion zwischen Menschen und Sprachmodellen beschäftigt — eine unterschätzte Fähigkeit.
Was Andrej Karpathy eine Woche später veröffentlichte
Am 4. April 2026 veröffentlichte Andrej Karpathy — Gründungsmitglied von OpenAI, ehemaliger KI-Direktor bei Tesla und eine der einflussreichsten Stimmen im Bereich maschinelles Lernen — ein GitHub Gist mit dem Titel „LLM Wiki“. Kein Code, kein Produkt, keine App. Ein „Idea File“ — ein konzeptionelles Dokument, das beschreibt, wie man Rohdaten von einem Sprachmodell zu einem strukturierten Wiki kompilieren lässt, statt bei jeder Anfrage die Dokumente von Grund auf neu zu durchsuchen.
Das Gist ging innerhalb von Stunden viral. Tausende Stars auf GitHub, dutzende Implementierungen, Blogposts auf Hacker News, Medium, Substack. Innerhalb einer Woche hatten mehrere Open-Source-Projekte das Muster in ihre Systeme integriert.
Karpathys Kernargument: Die Art, wie die meisten Menschen heute mit Sprachmodellen und Dokumenten arbeiten, ist RAG — Retrieval Augmented Generation. Man lädt Dateien hoch, stellt eine Frage, das Modell sucht relevante Stellen und generiert eine Antwort. Das funktioniert, aber es gibt keine Akkumulation. Jede Anfrage startet bei null. Stelle ich eine komplexe Frage, die fünf verschiedene Dokumente erfordert, muss das Modell jedes Mal von vorn suchen und zusammenfügen. Morgen wieder. Übermorgen erneut.
Ein Wiki löst das, weil es zustandsbehaftet ist. Wissen wird einmal kompiliert, strukturiert, vernetzt — und dann gepflegt. Nicht bei jeder Frage neu zusammengesucht, sondern einmal aufgebaut und inkrementell erweitert. Die KI übernimmt dabei die Arbeit, an der Menschen regelmäßig scheitern: Querverweise aktuell halten, Widersprüche erkennen, verwaiste Einträge finden, neue Informationen in bestehende Strukturen einpflegen.
Karpathys eigenes Wiki umfasst laut Gist rund 100 Artikel und 400.000 Wörter. Sein Setup basiert auf reinem Markdown und Obsidian — kein Embedding-Modell, keine Vektordatenbank, keine Hybrid-Suche. Das Sprachmodell navigiert das Wiki über die Querverweise und den Index, nicht über semantische Ähnlichkeit.
Mein System entstand unabhängig davon, bevor Karpathys Gist erschien. Nicht um Priorität zu beanspruchen, das wäre auch lächerlich, sondern weil es etwas zeigt: Dasselbe Muster entsteht gerade an vielen Stellen gleichzeitig, unabhängig voneinander. Nicht weil einer vom anderen abschaut, sondern weil das zugrunde liegende Problem überall dasselbe ist.
Wer ernsthaft mit großen Wissensbeständen und Sprachmodellen arbeitet, stößt irgendwann an die Grenzen von RAG — und landet bei wenigstens ähnlichen Lösungsansätzen, obgleich, wie in meinem Fall, man dies nur konzeptionell erschließen kann.
Die Architekturen unterscheiden sich im Detail. Karpathys Ansatz ist eleganter: reines Markdown, kein Embedding-Modell nötig, das Sprachmodell navigiert über Struktur und Verlinkung. Meiner hat eine Hybrid-Suche mit Reranking, was bei fachbegriffslastigen Anfragen Vorteile hat — wenn ich nach „NavBoost“ oder „E-E-A-T“ suche, brauche ich exakte Treffer, nicht nur semantische Nähe. Unterschiedliche Lösungen, leicht unterschiedliche Probleme, dasselbe Grundprinzip.
Was mich an Karpathys Veröffentlichung am meisten interessiert, ist nicht die technische Architektur. Es ist ein Satz aus seinem Gist, der das ganze Muster auf den Punkt bringt: Die Schwierigkeit beim Aufbau einer Wissensbasis war noch nie das Lesen der Informationen — sondern das Pflegen. Und genau darin sind Sprachmodelle gut.
Was meine Wissensbibliothek kann — und was nicht
305 Quellen sind aktuell in der Bibliothek. Webseiten, YouTube-Transkripte, PDFs, eigene Textdateien. Deutsch und Englisch. Das Embedding-Modell ist mehrsprachig, es versteht beide Sprachen im selben Vektorraum, kann also eine deutsche Frage gegen einen englischen Quellentext matchen. Die gesamte Infrastruktur läuft lokal auf meinem Windows-Rechner, ohne GPU. Hardwarekosten: null. Softwarekosten: null — alles Open Source. Die einzigen laufenden Kosten sind ein geschätzter Euro für das LLM-gestützte Chunking beim Import neuer Quellen über die Anthropic-API.
Was das System tatsächlich leistet: Ich kann eine Fachfrage stellen und bekomme die Stellen aus meinem Quellenmaterial zurück, die diese Frage beantworten. Nicht eine vage Zusammenfassung, nicht eine halluzinierte Synthese — sondern konkrete Passagen aus konkreten Quellen, bewertet nach Relevanz. Ich kann Claude beauftragen, eine Wiki-Seite zu einem Konzept zu erstellen, und Claude kompiliert sie aus den Rohdaten — mit Quellenangaben, Querverweisen und einer automatischen Prüfung auf Widersprüche zu bestehenden Seiten. Ich kann den gesamten Wissensbestand per Lint-Funktion auf Qualität prüfen lassen: tote Querverweise, verwaiste Seiten, fehlende Metadaten, veraltete Einträge, Duplikate.
Was ist eine Lint-Funktion?
Ein Lint — der Begriff stammt aus der Softwareentwicklung — ist ein automatisierter Qualitätscheck. In meinem Fall prüft er das Wiki auf tote Querverweise, verwaiste Seiten ohne Verlinkung, fehlende Metadaten, zu kurze Einträge, fehlende Quellenangaben, veraltete Inhalte und mögliche Duplikate. Ich wusste vor diesem Projekt nicht, was ein Lint ist. Claude hat die Funktion vorgeschlagen, als das Wiki auf über 30 Seiten angewachsen war und die manuelle Qualitätskontrolle unübersichtlich wurde. Es war einer der Momente, in denen mir klar wurde, dass die KI nicht nur ausführt, was ich anweise — sondern Probleme erkennt, die ich noch nicht gesehen habe.
Was das System nicht leistet: Es zieht keine fachlichen Schlüsse für mich. Es recherchiert. Die Argumente baue ich. Die Entscheidung, welche Quellen relevant sind und wie sie zueinander stehen, liegt bei mir.
Und jetzt die ehrliche Einordnung, die in einem Artikel wie diesem nicht fehlen darf.
Ich kann nicht beurteilen, ob der Code gut ist. Ich bin kein Programmierer. Ich kann nicht einschätzen, ob die Architektur elegant ist, ob die Datenbankwahl optimal war oder ob ein Softwareentwickler beim Blick auf den Code nicken oder den Kopf schütteln würde. Was ich sehe: Es funktioniert. Es löst das Problem, das ich hatte. Und es ist über Wochen entstanden, in einem Prozess, bei dem kein einziger Schritt beim ersten Mal fehlerfrei lief.
Karpathy selbst nennt diese Art von System eine „collection of scripts“. Das trifft es vermutlich. Es ist kein Produkt, das man installiert und benutzt. Es ist ein Werkzeug, das genau einen Zweck erfüllt — und diesen Zweck erfüllt es sowas von.
Was ich beurteilen kann, ist der Wert dessen, was das System tut. Und der liegt nicht im Code, der ist bestimmt austauschbar. Er liegt im Konzept, das ich am Anfang dieses Artikels beschrieben habe: eine Infrastruktur, die dafür sorgt, dass das Modell bei meinen Quellen bleibt.
Warum diese Art von Wissensorganisation über SEO hinausgeht
Ich habe dieses System für einen sehr spezifischen Anwendungsfall gebaut: SEO-Fachartikel bzw. Quellen-Infos recherchieren, und das auf Basis eines kuratierten Quellenkorpus. Aber das Muster dahinter ist nicht SEO-spezifisch. Es ist überall anwendbar, wo jemand Wissen aus vielen Quellen zusammenführen, durchsuchbar machen und über Zeit pflegen muss.
Ein Steuerberater, der Mandanten zu komplexen Sachverhalten berät und dafür Urteile, BMF-Schreiben und Kommentierungen aus verschiedenen Quellen zusammenführen muss. Eine Ärztin, die aktuelle Studien zu einem Krankheitsbild sammelt und bei der nächsten Fallbesprechung gezielt darauf zugreifen will. Ein Projektmanager, der Support-Tickets und Kundengespräche in einer durchsuchbaren Wissensbasis zusammenführen möchte, statt jedes Mal von vorn durch Confluence-Seiten zu scrollen.
Das sind nach meiner eigenen Erfahrung in der Agenturarbeit (*räusper*, Projektmanagement, *räusper*) keine hypothetischen Beispiele. Das sind Situationen, in denen Menschen heute bereits mit dem gleichen Problem kämpfen, das ich hatte: zu viel Wissen, zu verstreut, zu aufwendig zu pflegen.
Das System, das Karpathy beschreibt, gilt über SEO hinaus: Wissen wird nicht bei jeder Frage neu zusammengesucht, sondern einmal kompiliert und dann gepflegt.
Dass dieses Muster gerade gleichzeitig an vielen Stellen entsteht — Karpathys LLM Wiki, diverse Open-Source-Implementierungen, und offenbar auch ein SEO-Spezialist aus Lübeck, der kein Python kann — ist kein Zufall, kann kein Zufall sein. Die Werkzeuge sind da. Die Konzepte sind verstanden. Was bisher fehlte, war die Verbindung zwischen den großen Sprachmodellen und den persönlichen Wissensbeständen der Menschen, die mit ihnen arbeiten. Diese Verbindung wird gerade gebaut.
Meiner ist SEO. Deiner muss es nicht sein.
Über diesen Artikel
Die inhaltliche Verantwortung für jeden Artikel auf diesem Blog liegt bei mir, Patrick Stolp. Thema, These, Recherche und fachliche Prüfung sind meine Arbeit – hier wird nichts veröffentlicht, das ich nicht selbst konzipiert, geschrieben und als korrekt verifiziert habe. Generative KI (Claude von Anthropic) kommt punktuell als Werkzeug zum Einsatz – etwa für Formulierungsentwürfe oder das Gegenlesen technischer Erklärungen. Kein KI-Output landet ungeprüft oder unverändert auf dieser Seite. Beitragsbilder werden mit Google Nano Banana 2 erstellt.
Mehr dazu in meinen Redaktionsrichtlinien.