Wie KI-Suche funktioniert: Vektoren, BERT und Query Fan-out

Nein, ChatGPT war nicht der Startschuss
November 2022. OpenAI launcht ChatGPT, und die SEO-Branche steht Kopf. Plötzlich ist alles anders, alles neu, alles „disruptiv“. GEO sei das neue SEO, heißt es. Wer nicht sofort auf den Zug aufspringe, sei morgen irrelevant. Nun, wie so oft lohnt es sich, einen Schritt zurückzutreten und auf die Fakten zu schauen. Denn die Geschichte der KI-Suche beginnt nicht im November 2022. Sie beginnt mindestens sieben Jahre früher – und zwar bei Google selbst.
2015 führt Google RankBrain ein – das erste Machine-Learning-basierte Ranking-Signal in der Google-Suche. Keine festen Regeln mehr, die ein Programmierer definiert hat, sondern ein System, das aus Daten lernt. Das ist, auch wenn es damals kaum jemand so eingeordnet hat, der eigentliche Startschuss der KI-basierten Suche.
2017 veröffentlicht Google Research das Paper „Attention Is All You Need“ – die Transformer-Architektur. Dieses Paper ist das Fundament, auf dem heute sämtliche modernen Large Language Models basieren. Auch ChatGPT. Auch Claude. Auch Gemini. Ohne dieses Google-Paper gäbe es keinen einzigen der KI-Chatbots, die heute als „Google-Killer“ gehandelt werden.
2018 integriert Google BERT in die Suche – ein Large Language Model, das das Sprachverständnis der Suchmaschine revolutioniert. Seit BERT versteht Google nicht mehr nur einzelne Wörter, sondern Bedeutung, Kontext und Absicht. Das ist keine Kleinigkeit. Das ist der Moment, in dem Google aufhört, eine Keyword-Maschine zu sein.
2020 veröffentlicht OpenAI „Language Models are Few-Shot Learners“ – das GPT-3-Paper. Die zugrunde liegende Architektur? Googles Transformer. OpenAI hat sie weiterentwickelt, skaliert und in ein Chat-Interface gepackt. Aber die Basis ist und bleibt Google-Technologie.
Und dann, 2022, kommt ChatGPT – und alle tun so, als sei die Welt über Nacht eine andere geworden.
Versteh mich nicht falsch: ChatGPT hat die öffentliche Wahrnehmung von KI radikal verändert. Aber die technologische Grundlage existierte längst. Google ist seit 2015 eine KI-basierte Suchmaschine. Und die SEO-Branche hätte das die ganze Zeit wissen können – wenn sie weniger auf Hype und mehr auf Research Papers geschaut hätte.
Was ist Machine Learning – und warum ist das relevant?
Viele sagen: „Google ist ein Algorithmus.“ Stimmt. Aber welche Art von Algorithmus? Denn genau hier liegt der entscheidende Unterschied – und das Missverständnis, das die halbe SEO-Branche seit Jahren in die Irre führt.
Ein klassischer Algorithmus funktioniert so: Ein Programmierer schreibt feste Regeln, die Maschine wendet sie auf Daten an und liefert ein Ergebnis. Beispiel: „Wenn das Keyword fünfmal im Text vorkommt, ist die Seite relevant.“ Die Maschine ist hier nichts weiter als ein schneller Taschenrechner. Sie wendet Formeln an, mehr nicht. Das Problem: So ein System scheitert an Komplexität – und es ist leicht manipulierbar. Genau das war die Ära der Keyword-Dichte.
Ein Machine-Learning-Algorithmus dreht die Logik um. Statt „Daten + Regeln = Antwort“ heißt es hier: „Daten + Antworten = Regeln.“ Die Maschine bekommt keine Regeln vorgegeben – sie leitet sie selbst aus riesigen Datenmengen ab. Sie erkennt Muster. Sie versteht Bedeutung, nicht nur Zeichenketten. Kein Mensch hat Google gesagt, wie Sprache funktioniert. Google hat es aus Milliarden von Texten und Nutzerinteraktionen selbst gelernt.
Das ist kein akademisches Detail. Das ist der Kern der Sache. Denn wenn du verstehst, dass Google seit 2018 (BERT) ein System ist, das Sprache durch maschinelles Lernen versteht, dann verstehst du auch, warum Keyword-Stuffing nicht nur nutzlos, sondern kontraproduktiv ist. Und du verstehst, warum die gleiche Technologie in KI-Chatbots und in der Google-Suche steckt.
Ein Gedankenexperiment: Bananen und Äpfel
Um das greifbar zu machen, ein Beispiel. Stell dir vor, Millionen von Nutzern suchen bei Google nach „Banane“ – und klicken massenhaft auf Bilder von Äpfeln. Was passiert?
Schritt 1: Nutzer sucht „Banane“.
Schritt 2: Die Mehrheit klickt auf Apfelbilder statt auf Bananenbilder.
Schritt 3: Google passt die Ergebnisse an – bei „Banane“ werden nun Apfelbilder ausgespielt.
Schritt 4: Die Bedeutung der Suchanfrage „Banane“ hat sich verändert. Nicht durch ein Wörterbuch, nicht durch einen Redakteur, sondern durch Nutzerverhalten.
Das klingt absurd, ist aber exakt der Mechanismus, der tagtäglich im Hintergrund läuft – nur eben weniger offensichtlich als im Banane-Apfel-Beispiel. Im Fachjargon ist das nichts anderes als Implicit Reinforcement Learning from Human Feedback in massiver Skalierung.
Und jetzt der entscheidende Punkt: Query-Semantik ist keine Wörterbuch-Semantik. Die Bedeutung einer Suchanfrage wird nicht durch Definitionen festgelegt, sondern durch das kollektive Verhalten der Nutzer. Wenn Millionen Menschen bei „Autokredit“ auf Vergleichsseiten klicken statt auf Ratgeberartikel, dann ist die Bedeutung von „Autokredit“ für Google: Vergleich. Nicht weil es im Duden steht, sondern weil die Daten es zeigen.
Das ist auch das, was nach einem Google Core Update passiert: Neue Datensätze fließen ein, Nutzersignale werden neu gewichtet – und plötzlich verschiebt sich die Bedeutung ganzer Suchbegriffe. Nicht weil Google den Algorithmus umgeschrieben hat, sondern weil die Maschine aus neuen Daten neue Muster gelernt hat.
Lexikalische vs. semantische Suche: Warum Keywords nicht mehr zählen
Vielleicht kennst du das: Deine SEO-Agentur sagt dir, du sollst „das Keyword möglichst oft auf der Seite unterbringen“. Keyword-Dichte optimieren, Synonyme einstreuen, am besten noch die exakte Suchphrase in jeden zweiten Absatz schreiben. Nun, das war tatsächlich mal eine funktionierende Strategie. Vor etwa sieben Jahren. Seitdem ist sie nicht nur wirkungslos – sie schadet aktiv.
Der Unterschied lässt sich am besten an einem konkreten Beispiel zeigen. Stell dir zwei Webseiten vor, die für die Suchanfrage „Autokredit“ ranken wollen.
Seite A – die lexikalische Variante: Ein Ratgeber-Text, in dem das Wort „Autokredit“ zwölfmal vorkommt. „Was ist ein Autokredit? Ein Autokredit ist ein zweckgebundener Kredit. Den Autokredit beantragen Sie bei Ihrer Bank. Beim Autokredit-Vergleich achten Sie auf den Autokredit-Zinssatz …“ Du merkst, wohin das führt. Das ist Keyword-Stuffing, auch wenn es viele nicht so nennen würden.
Seite B – die semantische Variante: Eine Vergleichsseite. Kein einziges Mal das Wort „Autokredit“ – stattdessen „Pkw-Darlehen“, „Autofinanzierung“, konkrete Anbieter, Zinssätze, Laufzeiten, ein Vergleichsrechner. Das Thema ist glasklar, die Absicht bedient, das Vertrauen gegeben.
Welche Seite rankt? Seite B. Und zwar nicht knapp, sondern deutlich. Denn seit BERT (2018/19) bewertet Google nicht mehr, wie oft ein Keyword auf einer Seite vorkommt, sondern ob Thema, Absicht und Vertrauen zwischen Suchanfrage und Inhalt zusammenpassen. Google nennt dieses Prinzip „Things, not Strings“ – es geht um Entitäten und Konzepte, nicht um Zeichenketten.
Keine Theorie, sondern die Realität der Google-Suche seit mittlerweile sieben Jahren. Und trotzdem optimieren die meisten Agenturen immer noch so, als wäre es 2016. Ich sage das nicht, um zu provozieren – sondern weil es ein echtes Problem für Unternehmen ist, die dafür Geld bezahlen. Wer Keywords optimiert statt Semantik, optimiert auf ein System, das längst abgelöst wurde.
Vektoren: Wie Text zu Zahlen wird
Vielleicht erinnerst du dich noch an Mathematik aus der Oberstufe. Ich tue das schon, wenn auch mit Graus. Aber wie es im Leben so ist – manches davon braucht man dann doch irgendwann. In diesem Fall: Koordinatensysteme und Vektoren. Also Zahlenreihen, die sich irgendwo in einem mehrdimensionalen Raum verorten lassen. Und mit denen sich rechnen lässt.
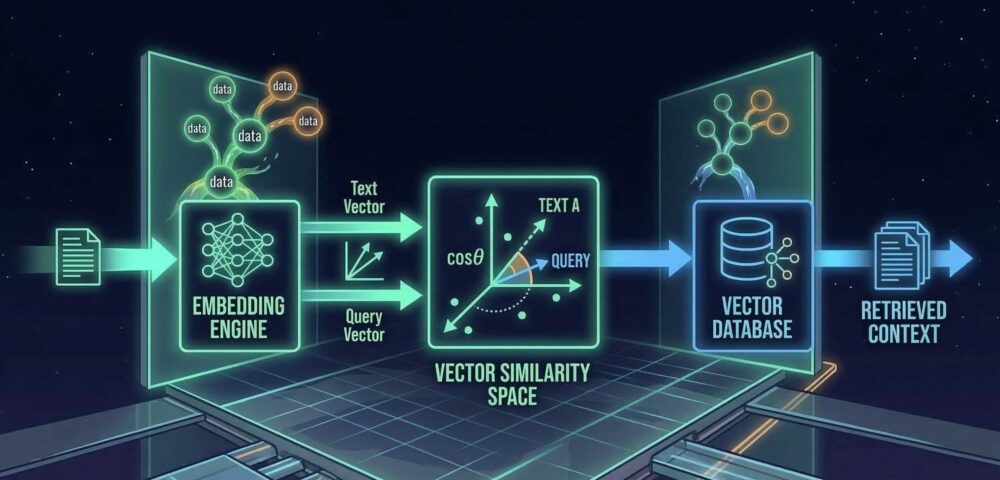
Warum ist das relevant? Weil KI – egal ob Google-Suche oder ChatGPT – nicht mit Wörtern arbeitet. Maschinen können keine Sprache lesen, zumindest nicht so, wie wir es tun. Um Texte vergleichen, sortieren und bewerten zu können, muss die Maschine alles in Zahlen umwandeln. Genauer gesagt: in Vektoren. Und das passiert auf drei Ebenen.
Ebene 1: Wörter. Jedes einzelne Wort wird zu einer Zahlenreihe, die seine Bedeutung repräsentiert. „Autokredit“ bekommt einen Vektor, „Pkw-Darlehen“ bekommt einen anderen – aber weil beide semantisch ähnlich sind, liegen ihre Vektoren im mathematischen Raum nah beieinander. Dieses Prinzip nennt sich Word2Vec und bildet die Grundlage für alles, was danach kommt.
Ebene 2: Textpassagen. Nicht nur einzelne Wörter, sondern ganze Absätze werden vektorisiert. Der Satz „Ein Autokredit ist ein zweckgebundenes Darlehen mit fester Laufzeit zur Pkw-Finanzierung“ ergibt eine Zahlenreihe, die seine inhaltliche Bedeutung als Ganzes abbildet – nicht die Summe der Einzelwörter, sondern den Sinn des Absatzes.
Ebene 3: Dokumente. Jede Webseite wird zu einem Vektor, der ihren thematischen Schwerpunkt repräsentiert. Hier fließen alle Absätze, Überschriften und Kontextsignale zusammen.
Und jetzt wird es spannend. Denn mit Vektoren lässt sich rechnen – und zwar auf eine Art, die fast magisch wirkt. Das bekannteste Beispiel: König − Mann + Frau = Königin. Klingt absurd, funktioniert aber mathematisch einwandfrei. Wenn man den Vektor von „Mann“ vom Vektor „König“ abzieht und den Vektor „Frau“ addiert, landet man im Vektorraum punktgenau bei „Königin“. Die Maschine hat das Konzept „Geschlecht“ als mathematische Richtung gelernt – ohne dass ihr jemand erklärt hat, was Geschlecht ist.
Nach exakt diesem Prinzip funktioniert sowohl die Google-Suche als auch jeder KI-Chatbot. Wenn du eine Suchanfrage eingibst oder einen Prompt schreibst, wird dieser in einen Vektor umgewandelt und mit den Vektoren aller indizierten Textpassagen und Dokumente verglichen. Je näher sich zwei Vektoren im Raum sind, desto relevanter ist der Treffer. In der Mathematik heißt dieses Ähnlichkeitsmaß Cosine Similarity.
Und hier schließt sich der Kreis zum Thema Keyword-Dichte. Je häufiger dieselben Wörter in einem Text vorkommen, desto „eindimensionaler“ wird sein Vektor. Der Text verliert an semantischer Vielfalt – und damit an Vergleichbarkeit. Die Maschine kann einen solchen Text schlechter den richtigen Themen und Nutzerabsichten zuordnen. Keyword-Stuffing ist, so betrachtet, das Gegenteil von Optimierung. Es macht den Inhalt für die KI unlesbarer, nicht lesbarer.
Unter der Haube: Wie Suchmaschine und KI-Chatbot arbeiten
Jetzt, wo wir wissen, wie Texte zu Vektoren werden und warum Bedeutung sich mathematisch vergleichen lässt, können wir uns anschauen, wie die Google-Suche und KI-Chatbots diese Technologie konkret einsetzen. Denn trotz aller Unterschiede in der Oberfläche – zehn blaue Links hier, synthetisierte Antwort dort – laufen unter der Haube erstaunlich ähnliche Prozesse ab. In vier Phasen.
Phase 1: Crawling
Hier gibt es schlicht keinen Unterschied. Sowohl Google als auch die Datenanbieter hinter ChatGPT, Perplexity und Co. schicken Bots durchs Web, die Webseiten aufrufen, auslesen und in eine Datenbank überführen. Der GPTBot von OpenAI funktioniert im Prinzip genauso wie der Googlebot. Wer crawlt, baut sich eine Wissensbasis auf – egal, ob daraus später eine Linkliste oder eine generierte Antwort entsteht.
Phase 2: Indizierung und Vektorisierung
Ab hier wird es interessant. Google indiziert und vektorisiert sowohl ganze Dokumente als auch Teile davon – Überschriften, Absätze, Tabellen. Das Ergebnis ist ein Dokumenten-Index plus eine Vektor-Datenbank. KI-Chatbots gehen einen Schritt weiter, beziehungsweise einen Schritt enger: Sie zerlegen Dokumente in einzelne Textabschnitte – sogenannte Chunks – und vektorisieren diese separat. Jeder Chunk steht für sich, als eigenständiger Informationsträger.
Klingt nach einem kleinen Unterschied, hat aber massive Konsequenzen für die Optimierung. Dazu gleich mehr.
Phase 3: Verarbeitung der Suchanfrage
Bei Google passiert Folgendes: Die Suchanfrage wird durch ein Sprachmodell (seit 2018 BERT) interpretiert, die Nutzerabsicht identifiziert, und passende Dokumente aus dem Index abgerufen. Eine Anfrage, eine Absicht, ein Ergebnisformat. Relativ linear.
Bei KI-Chatbots läuft der Prozess anders. Der Prompt wird nicht als eine einzelne Anfrage behandelt, sondern in mehrere parallele Teilanfragen aufgesplittet – ein Verfahren, das sich Query Fan-out nennt und auf das ich im nächsten Abschnitt ausführlich eingehe. Die KI identifiziert nicht eine Absicht, sondern alle vor- und nachgelagerten Absichten, die mit dem Prompt zusammenhängen könnten.
Phase 4: Ausgabe
Und hier liegt der Unterschied, den jeder sofort sieht. Google liefert eine sortierte Dokumentenliste – deterministisch. Gleiche Anfrage, gleicher Ort, gleiches Gerät, gleicher Zeitpunkt: immer dasselbe Ergebnis. Ein KI-Chatbot hingegen generiert eine synthetisierte Antwort – probabilistisch. Die Antwort wird Wort für Wort erzeugt, und bei jedem Token spielt ein Zufallsfaktor mit. Deshalb kann die gleiche Frage an ChatGPT dreimal hintereinander drei verschiedene Antworten liefern. Was das für die Messbarkeit von Sichtbarkeit bedeutet, wird Thema von Artikel 3 dieser Reihe.
Was heißt das für die Optimierung?
Der Kernunterschied lässt sich auf einen Satz runterbrechen: In SEO konkurrieren Dokumente. In GEO konkurrieren Textabschnitte. In der klassischen Suche wird deine Seite als Ganzes bewertet und gegen andere Seiten gerankt. In der KI-Suche wird jeder einzelne Absatz deiner Seite als eigenständiger Antwortkandidat behandelt. Ein mittelmäßiges Dokument mit einem brillanten Absatz kann in der KI-Suche zitiert werden – in der klassischen Suche würde es auf Seite drei versauern.
Die gute Nachricht: Crawling, Indizierung und Anfrageverarbeitung funktionieren im Kern fast identisch. Wer semantisch sauber optimiert, profitiert in beiden Welten. Der Hebel liegt in der Chunk-Logik – und darin, jeden Absatz so zu schreiben, als müsste er alleine bestehen können. Aber dazu mehr in Artikel 4 dieser Reihe.
Query Fan-out: Warum KI-Suche die gesamte Customer Journey abbildet
Wenn mich jemand fragt, was GEO wirklich von SEO unterscheidet – jenseits der Oberfläche, jenseits der Buzzwords –, dann ist Query Fan-out meine Antwort. Denn hier liegt der eine Mechanismus, der tatsächlich neu ist. Nicht halbwegs neu, nicht „irgendwie anders“ – sondern ein fundamental anderer Ansatz, Suchanfragen zu verarbeiten. Dokumentiert unter anderem in Googles Patent US20250321968A1 (Deep Search / Query Fan-out).
Was passiert bei einer klassischen Suchanfrage?
Nehmen wir das Beispiel „Autokredit“. In der klassischen Google-Suche läuft ein relativ linearer Prozess ab: BERT interpretiert die Anfrage, identifiziert die Hauptabsicht – in diesem Fall „Vergleich“ – und legt fest, welches Ergebnisformat dazu passt. Die Antwort: Vergleichsseiten. Google liefert eine Top-10-Liste, dominiert von Check24, Verivox und Co. Eine Absicht, ein Format, eine Ergebnisliste.
Aber „Autokredit“ ist natürlich mehr als nur ein Vergleich. Dahinter stecken Dutzende Teilfragen: Welche Finanzierungsarten gibt es? Was sind die Voraussetzungen? Wie läuft der Antrag? Was muss ich zur Bonität wissen? Diese Teilfragen bedient Google ebenfalls – aber verteilt auf Seite 2, 3, 4 und folgende der Suchergebnisse. Position 20+ für Finanzierungsarten, Position 42 für Voraussetzungen, Position 53 für Antragstipps. Die Information existiert, aber der Nutzer muss sich aktiv durch die Ergebnisse arbeiten, um sie zu finden.
Was passiert bei einem KI-Prompt?
Hier kommt Query Fan-out ins Spiel. Statt eine einzelne Absicht zu identifizieren, splittet die KI den Prompt „Autokredit“ in mehrere parallele Teilanfragen auf – jede mit einer eigenen Absicht. Vergleich, Finanzierungsarten, Funktionsweise, Voraussetzungen, Bonität, Antragstipps. All diese Teilfragen werden gleichzeitig gegen die Vektor-Datenbank abgeglichen, die relevantesten Chunks pro Teilfrage identifiziert und anschließend zu einer einzigen, zusammenhängenden Antwort synthetisiert.
Das Ergebnis: Was Google auf zehn Ergebnisseiten mit jeweils zehn Links verteilt, fasst die KI in einer Antwort zusammen. Der Nutzer bekommt nicht nur den Vergleich, sondern die gesamte Customer Journey – von der Erstinformation bis zum konkreten Antragstipp. In einem Durchlauf, ohne Klicken, ohne Scrollen.
Warum ist das so relevant für die Optimierung?
Weil sich damit verändert, wofür du überhaupt sichtbar sein kannst. In der klassischen Suche kämpfst du um einen Platz in den Top 10 für eine bestimmte Absicht. Wenn „Autokredit“ Vergleichsseiten bevorzugt und du einen Ratgeber anbietest, hast du gegen Check24 praktisch keine Chance auf Seite 1 – egal wie gut dein Content ist.
In der KI-Suche sieht das anders aus. Dein Ratgeber-Absatz zu Bonität und Voraussetzungen kann als Chunk in der synthetisierten Antwort landen – auch wenn du in den klassischen SERPs auf Position 42 stehst. Die KI bedient alle Teilfragen und sucht sich pro Teilfrage den besten verfügbaren Textabschnitt. Wer also für die Nebenfragen einer Customer Journey den besten Chunk liefert, kann in der KI-Antwort auftauchen, ohne jemals in den Top 10 bei Google gewesen zu sein.
Das heißt im Umkehrschluss aber auch: Wer nur auf die Hauptintention optimiert und die vor- und nachgelagerten Fragen ignoriert, verschenkt in der KI-Suche Sichtbarkeit. Fan-out belohnt thematische Vollständigkeit – und bestraft eindimensionale Inhalte.
RAG: Was passiert, wenn die KI keine Antwort hat?
Bisher haben wir uns angeschaut, wie KI-Systeme Inhalte indizieren, vektorisieren und bei Anfragen die passenden Chunks finden. Aber was, wenn die KI schlicht nichts weiß? Wenn jemand nach dem VW Bus California Test 2026 fragt und das Modell mit Trainingsdaten arbeitet, die im Frühjahr 2025 enden?
Genau hier kommt RAG ins Spiel – Retrieval Augmented Generation. Das Prinzip ist so simpel wie wirkungsvoll: Bevor die KI eine Antwort generiert, prüft sie, ob ihr Trainingswissen ausreicht. Falls nicht, startet sie eine Live-Suche – im Hintergrund, über eine Suchmaschine. Die gefundenen Inhalte werden als zusätzlicher Kontext in die Antwortgenerierung eingespeist. Die KI liest also im Moment der Anfrage externe Quellen und synthetisiert daraus ihre Antwort.
Und diese externen Quellen? Das sind ganz normale Webseiten. Deine Webseite, meine Webseite, Fachportale, Blogs, Testberichte. Kurz: SEO-Inhalte. Wenn ChatGPT eine aktuelle Frage nicht aus seinem Trainingswissen beantworten kann, greift es auf Google- oder Bing-Suchergebnisse zurück – und zitiert die Seiten, die dort ranken.
Für die Praxis heißt das zweierlei. Erstens: Wer in der klassischen Suche gut rankt, hat automatisch bessere Chancen, auch in KI-Antworten als Quelle aufzutauchen. Die beiden Welten sind nicht getrennt – RAG verbindet sie direkt. Zweitens: Aktualität wird zum echten Vorteil. Seiten mit frischen, regelmäßig aktualisierten Inhalten haben bei RAG-Anfragen einen strukturellen Vorteil gegenüber veralteten Evergreen-Artikeln, die seit drei Jahren nicht angefasst wurden.
RAG ist auch der Grund, warum SEO auf absehbare Zeit nicht überflüssig wird. Solange KI-Systeme auf externe Quellen angewiesen sind – und das werden sie bei allem, was über ihr Trainingswissen hinausgeht –, bleiben gut optimierte Webinhalte die Grundlage für KI-Antworten. Wer nicht crawlbar, nicht indizierbar und nicht semantisch verständlich ist, existiert für die KI schlicht nicht. Weder im Training noch im RAG-Prozess.
GEO ⊆ SEO – und der umgekehrte Schluss gilt nicht
Zeit, die Einzelteile zusammenzusetzen. Wir haben uns angeschaut, dass Google seit 2015 eine KI-basierte Suchmaschine ist. Dass ChatGPT auf Google-Technologie basiert. Dass beide Systeme Texte in Vektoren umwandeln und über Ähnlichkeitsvergleiche die relevantesten Inhalte finden. Dass Crawling, Indizierung und Anfrageverarbeitung im Kern fast identisch ablaufen. Und dass der echte Unterschied in zwei Punkten liegt: Query Fan-out – also die parallele Aufsplittung in Teilanfragen – und die Chunk-Logik, bei der einzelne Textabschnitte statt ganzer Dokumente als Antwortkandidaten dienen.
Was folgt daraus? Eine Formel, die einfach klingt, aber weitreichende Konsequenzen hat: Alle GEO-Maßnahmen sind SEO-Maßnahmen. Aber nicht alle SEO-Maßnahmen sind GEO-Maßnahmen. Oder mathematisch ausgedrückt: GEO ⊆ SEO – GEO ist eine echte Teilmenge von SEO.
Wer natürliche Sprache schreibt statt Keywords zu stopfen, profitiert in beiden Welten. Wer saubere Überschriften-Hierarchien nutzt, seine Absätze eigenständig verständlich formuliert und thematisch vollständig abdeckt, optimiert gleichzeitig für Google und für ChatGPT. Wer hingegen reine SEO-Maßnahmen betreibt, die auf den Faktor Mensch setzen – Nutzersignale, Klickverhalten, visuelle Psychologie –, der optimiert für Google, aber nicht zwingend für KI-Chatbots. Denn die KI hat keinen Browser, klickt auf keine Buttons und lässt sich nicht von einem hübschen Hero-Image beeindrucken.
Wer also GEO schreit und SEO für tot erklärt, hat weder das eine noch das andere verstanden. Und wer meint, SEO könne so weiterlaufen wie bisher und man müsse GEO ignorieren, übrigens auch nicht. Die richtige Antwort liegt – wie so oft – in der Mitte: Semantische SEO, die seit Jahren best practice sein sollte, ist automatisch auch GEO. Wer das bereits macht, muss wenig ändern. Wer es nicht macht, hat ein doppeltes Problem.
Soweit zur Theorie. In der Praxis stellt sich natürlich sofort die Frage: Wenn ich für KI-Suche optimiere – wie messe ich dann, ob es funktioniert? Rankings in ChatGPT tracken? Brand Mentions zählen? Spoiler: So einfach ist es leider nicht. Warum, und was stattdessen funktioniert, darum geht es im nächsten Artikel.
Über diesen Artikel
Die inhaltliche Verantwortung für jeden Artikel auf diesem Blog liegt bei mir, Patrick Stolp. Thema, These, Recherche und fachliche Prüfung sind meine Arbeit – hier wird nichts veröffentlicht, das ich nicht selbst konzipiert, geschrieben und als korrekt verifiziert habe. Generative KI (Claude von Anthropic) kommt punktuell als Werkzeug zum Einsatz – etwa für Formulierungsentwürfe oder das Gegenlesen technischer Erklärungen. Kein KI-Output landet ungeprüft oder unverändert auf dieser Seite. Beitragsbilder werden mit Google Nano Banana 2 erstellt.
Mehr dazu in meinen Redaktionsrichtlinien.